Linux uses Virtual Memory (VM) that acts as a logical layer between application memory requests and physical memory (RAM). VM abstraction hides the complexity of platform specific physical memory implementation from the application. When application accesses virtual addresses exported by VM, hardware MMU raises an event to tell the kernel that an access has occurred to an area of memory that does not have physical memory mapped to it. This event results in an exception, called Page Fault, that is serviced by Linux kernel by mapping a faulted virtual address to physical memory page.
A page is simply a group of contiguous linear addresses in physical memory. Page size is 4 KB on x86 platform. Virtual addresses are transparently mapped to physical memory by collaboration of hardware ( MMU, Memory Management Unit) and software ( Page Tables). Virtual to physical mapping information is also cached in hardware, called TLB (Translation Lookaside Buffer), for later reference to allow quick lookup into physical memory locations.
 |
| Virtual to Physical Page Translation |
A page is simply a group of contiguous linear addresses in physical memory. Page size is 4 KB on x86 platform. Virtual addresses are transparently mapped to physical memory by collaboration of hardware ( MMU, Memory Management Unit) and software ( Page Tables). Virtual to physical mapping information is also cached in hardware, called TLB (Translation Lookaside Buffer), for later reference to allow quick lookup into physical memory locations.
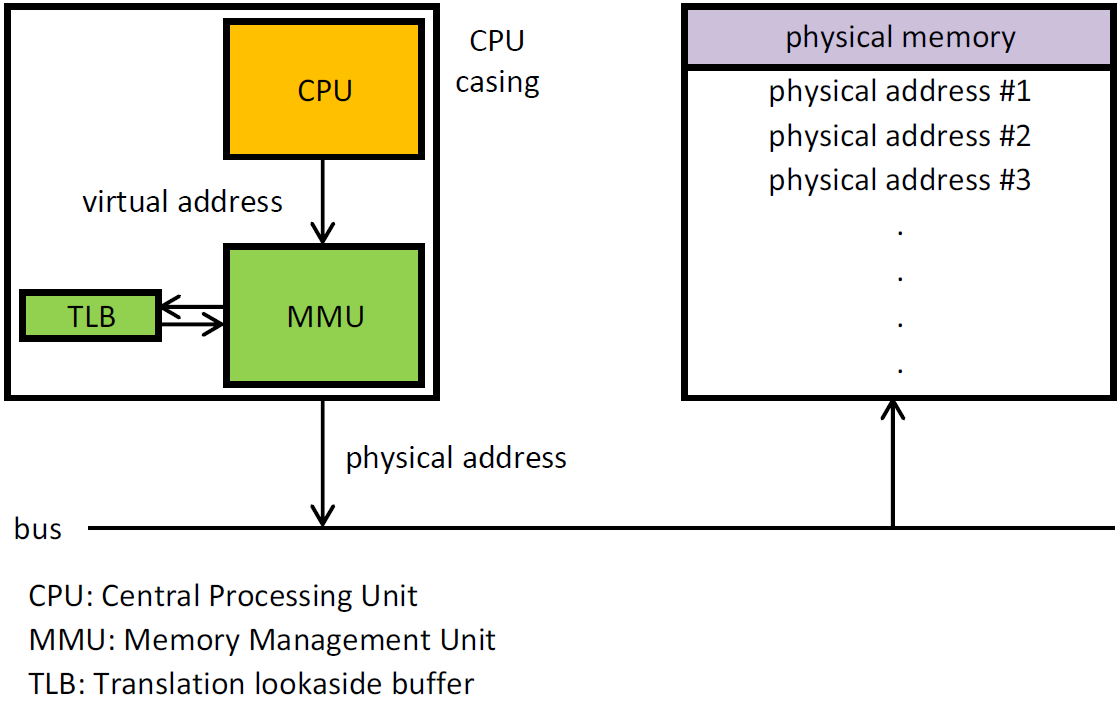 |
| Virtual to physical memory mapping |
VM abstraction offers several benefits:
- Programmers do not need to know physical memory architecture of the platform. VM hides it and allows writing architecture independent code.
- Process always see linear contiguous range of bytes in its address space, regardless of how fragmented the physical memory.
- For example: when application allocates 10 MB of memory, Linux kernel reserves 10 MB of contiguous virtual address range in the process address space. Physical memory locations where these virtual address range is mapped may not be contiguous. Only part that is guaranteed to be contiguous in the physical memory is the size of the page (4 KB).
- Faster startup due to partial loading. Demand paging loads instructions as they are referenced.
- Memory sharing. A single copy of library/program in physical memory can be mapped to multiple process address space. Allows efficient use of physical memory. "pmap -X <pid>" can be used to find what process resident memory is shared by other process or private.
- Several programs with memory footprints bigger than physical memory can run concurrently. Kernel behind the scene relocates least recently accessed pages to disk (swap) transparently.
- Processes are isolated into its own virtual address spaces and thus cannot affect or corrupt other process memory.
Two processes may use same virtual addresses, but these virtual addresses are mapped to different physical memory locations. Processes that attach to same shared memory (SHM) segment will have their virtual addresses mapped to same physical memory location.
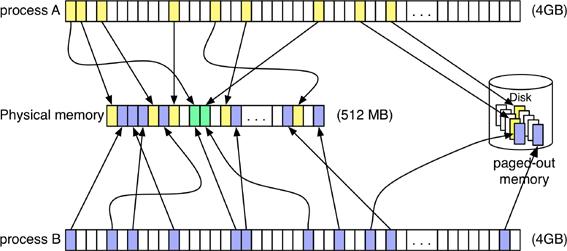 |
| Process address space can span to 32-bit or 64-bit. 32-bit address space is limited to 4GB, as compared to hundreds of Terabytes for 64-bit address space. Size of process address space limits the amount of physical memory application can use. |
Process virtual address space is composed of memory segments of type: Text, Data, Heap, Stack, Shared (SHM) memory and mmap. Process address space is defined as the range of virtual memory addresses that are exported to processes as its environment. Process address map can be viewed using "pmap -X <pid>".
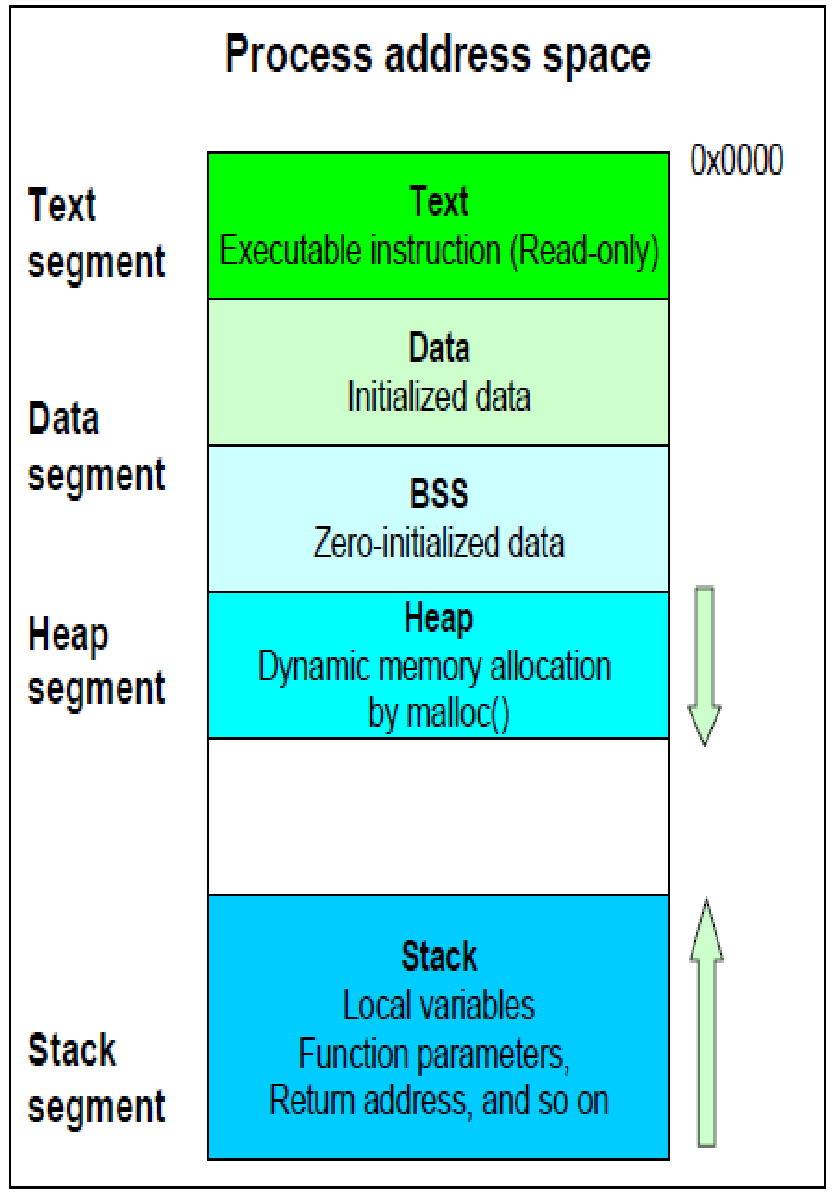 |
| various memory segments that are part of process address space |
Each memory segment is composed of linear virtual address range with starting and ending addresses, and are backed by some backing store like: filesystem or swap. Page fault is serviced by filling physical memory page from the backing store. Also, during memory shortages, data cached in physical memory pages is migrated to its backing store. Process "Text" memory segments is backed by executable file on the file system. Stack, heap, COW (Copy-on-Write) and shared memory pages are called anonymous (Anon) pages and are backed up by swap (disk partition or file). When swap is not configured, anonymous pages cannot be freed and are thus locked into memory considering no place to migrate data from these physical pages during memory shortages.
When process calls malloc() or sbrk(), kernel creates a new heap segment in the process address space and reserves the range of process virtual addresses that can be accessed legally. Any reference to a virtual address outside of reserved address range results in a segmentation violation, that kills the process. Physical memory allocation is delayed until process accesses the virtual addresses within the newly created memory segment. That means, application performing large 50GB of malloc and touching (page faulting) only 10 MB range of virtual addresses will consume only 10 MB of physical memory. One can view physical and virtual memory allocation per process using "ps", "pidstat" or "top" (Where: SIZE represents size of virtual memory segment and RSS represents allocated physical memory). Also, "pmap -X <pid>" can be used for detail view of type of process level memory allocation.
Physical memory pages used for program Text and caching file system data (called page cache) can be freed quickly during memory shortages considering data can always be retrieved from the backing store (file system). However, to free anonymous pages, data needs to be written to swap device before it can be freed.
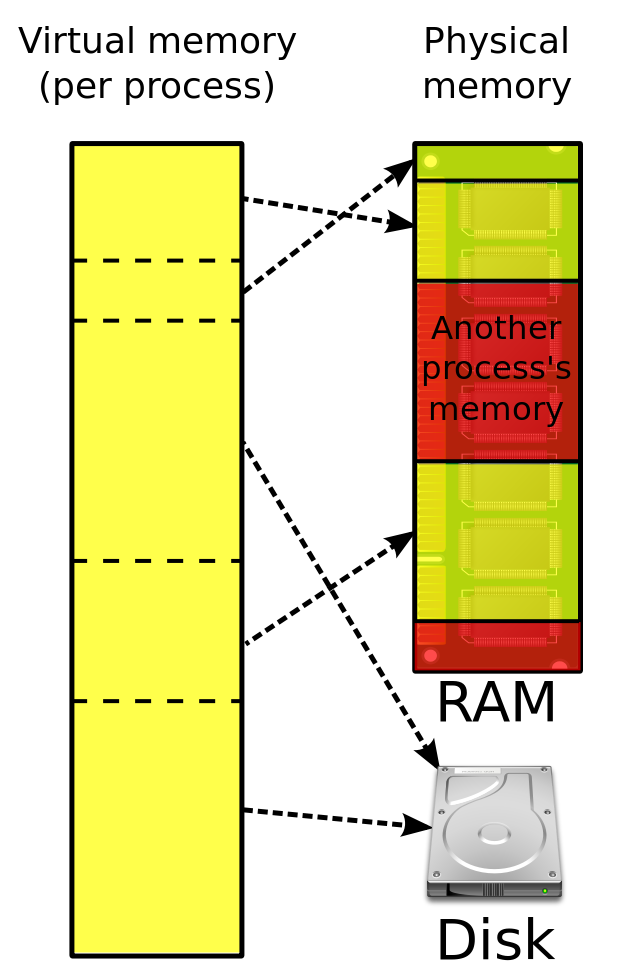 |
| Anonymous memory segments (heap, stack, cow, shared memory) are backed by swap (Disk) |
Linux Memory Allocation Policy
Process memory allocation is controlled by Linux memory allocation policy. Linux offers three different modes of memory allocations depending on the value set for tunable, vm.overcommit_memory
- Heuristic overcommit (vm.overcommit_memory=0): Linux default mode allows processes to overcommit "reasonable" amount of memory as determined by internal heuristics, that takes into account: free memory and free swap. In addition to this, memory that can be freed by shrinking the file system cache and kernel slab caches (used by kernel drivers and subsystems) is also taken into consideration.
- Pros: Uses relaxed accounting rules and it is useful for program that typically requests more memory than actually uses. As long as, there is a sufficient free memory and/or swap available to meet the request, process continue to function.
- Cons: Linux kernel makes no attempt to reserve physical memory on behalf of process, unless process touches (access) all virtual addresses in the memory segment.
- Example, Let say application, myapp, allocates 50 GB of memory, but touches only 10 GB. 40 GB of physical memory not touched by myapp is available for other applications. If any other application(s) or malicious program touches all available free memory before "myapp" get to touch it, it could trigger OOM (Out Of Memory) Killer that may terminate "myapp" in a desperate attempt to find candidates that can be killed to free memory.
- Always overcommit (vm.overcommit_memory=1): Allows process to overcommit as much memory as it wants and it always succeed.
- Pros: Wild allocations are permitted considering no restrictions on free memory or swap.
- Cons: Same as Heuristic overcommit. Application can malloc() TBs on a system with few GBs of physical memory. No failure until all pages are touched and that triggers OOM Killer.
- Strict Overcommit (vm.overcommit_memory=2): Prevents overcommit by reserving both virtual memory range and physical memory. No overcommit means no OOM Killer. Kernel keeps track of amount of physical memory reserved or already committed. "cat /proc/meminfo" reports metrics such as: CommitLimit, Committed_AS to help estimate memory available for allocation. Since strict overcommit mode does not take free memory and swap into consideration, one should not use free memory or swap metrics (reported by free, vmstat ) to discover memory available. To calculate current overcommit or allocation limit, one should use the equation: "CommitLimit - Committed_AS". Kernel tunable "vm.overcommit_ratio" sets overcommit limit for this mode. Overcommit limit is set to: Physical Memory x overcommit_ratio + swap. Overcommit limit can be raised by setting vm.overcommit_ratio tunable to a bigger value (default 50% of physical memory).
- Pros: Disables OOM Killer. Failure at the startup has lower production impact than being killed by OOM Killer while serving production load. Solaris OS offers only this mode. Strict overcommit does not use free memory/swap for overcommit limit calculations.
- Cons: No overcommit allowed. Memory allocated but not used by application may not be used by other application. A new program may fail to allocate memory even when the system is reporting plenty of free memory. This is due to reservation against the physical memory on behalf of existing processes. Monitoring for free memory becomes tricky. Some badly written applications do not handle memory allocation failures. Inability to check memory failures may results in corrupted memory and random hard to debug failures.
- Note: Memory not used by the application can still be used for filesystem cache considering page cache memory can be freed when application needs it.
NOTE: For both heuristic and strict overcommit, the kernel reserves a certain amount of memory for root. In heuristic mode, 1/32nd of the free physical memory. In Strict overcommit mode it is 1/32nd of the percent of real memory that you set. This is hard coded in kernel and cannot be tuned. That means a system with 64GB will reserve 2GB for root user.
What causes OOM Killer
Criteria used to find the candidate process some time kills the most critical process. There are few options available to deal with OOM Killer:
- Disable OOM Killer by changing kernel memory allocation policy to strict overcommit.
- $sudo sysctl vm.overcommit_memory=2
- $sudo sysctl vm.overcommit_ratio=80
- Opt out the critical process from OOM Killer consideration.
- $ echo -17 > /proc/<pid-critical-process>/oom_adj
- Opting out critical server process may sometime not be enough to keep system functioning. Kernel still has to kill processes in order to free memory. In some cases, automated reboot server to deal with OOM Killer may the better option.
- $sudo sysctl vm.panic_on_oom=1
- $sudo sysctl kernel.panic="number_of_seconds_to_wait_before_reboot"
File System Cache Benefits
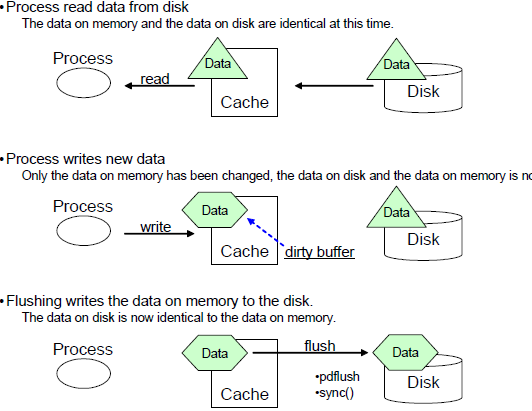
Linux uses free memory that is not being used by application for caching file system pages and disk blocks. Memory used by file system cache is counted as free memory and available when needed (after writing modified pages to backing store or disk). Linux "free" reports file system cache memory as free memory. Benefit of having file system cache is improved performance of application file system reads and writes:
- Read: When application reads from a file, kernel performs a physical IO to read data blocks from the disk. Data is cached in the file system cache for later use to avoid physical read. When application requests the same block, it only requires a logical IO (reading from filesystem page cache) and that improves application performance. Also, file systems prefetch (read ahead) blocks, when sequential IO pattern is detected, in an anticipation that application will request next adjacent blocks. This also help reduce IO latencies.
- Write: When application writes to a file, kernel caches data into page cache and acknowledges completions (called buffer writes). Also file data sitting in filesystem cache can be updated multiple times (called write cancelling) in memory before kernel schedules dirty pages to be written to disk.
File System cache improves both read and write performance
Dirty pages in file system cache are written by "flusher" (old name is pdflush) kernel thread. Dirty pages are flushed periodically when the proportion of dirty buffers in memory exceeds a certain threshold (kernel tunable). File system cache improves application IO performance by hiding storage latencies.
HugeTLB or HugePages Benefits
 |
| TLB miss results in walk to memory resident page tables |
As discussed earlier,TLB (Translation Lookaside buffer), integrated onto a cpu chip, caches virtual to physical translation. When translation is not found in TLB (event is called TLB miss), it results in expensive walk to memory resident page tables to find virtual to physical memory translation. TLB cache hit is becoming more important due to increasing disparity in cpu and memory speed and memory density. Frequent TLB miss may negatively impact application performance. TLB is a scarce resource on cpu chip and Linux kernel tries to make best use of limited TLB cache entries. Each TLB cache entry can be programmed to provide access to contiguous physical memory addresses of various sizes: 4 KB, 2 MB or 1 GB. Linux HugeTLB feature allows application to use large pages: 2 MB, 1 GB than the default 4 KB size.
 |
| Intel Haswell core has 64 entries for caching 4 KB page translation, 32 entries for 2 MB and 4 entries for 1 GB pages in L1 DTLB. There is also a unified (shared) L2 TLB that can hold translations for 1024 4 KB or 2 MB pages. Once the virtual address has been calculated, processor probes the TLB cache for v->p translation and then fetches the data in 64 bytes chunk from the physical memory location into L1/L2 hardware caches |
Pros and Cons of Linux HugeTLB feature:
Pros:
- HugeTLB may help reduce TLB misses by covering bigger process address space. For Intel Haswell processor:
- 4 KB page can cover: 64x4 + 1024x4 = 4 MB
- 2 MB page can cover: 32x2048 +1024x2048 = 2 GB
- 1 GB page can cover: 4GB
- TLB miss with HugeTLB is cheaper to service. Virtual to physical memory translation for 4KB pages via page tables require multiple levels of translations (4 levels for standard 48-bit virtual address space). Larger page size require fewer page table entries and levels are shallower. This reduces memory latency due to 2 level instead of 4 level page tables access and physical memory used for page table translation.
- Reduces page fault rates. Each page fault can fill 2 MB or 1GB physical memory than 4 KB. Thus makes the application to warm up much faster.
- Application performance improvement with HugeTLB depends on application access pattern. If application access pattern shows data locality, HugeTLB will help. However, if application reads from random locations or only few bytes from each page (large hash table lookup) and the working set is too big to fit in TLB cache, then 4 KB page size may offer better performance.
- 1 GB page may offer best performance when working set fits in 4GB physical memory. Even when the working set is bigger, page table walk with 1GB will be much quicker.
- Huge Pages are locked in memory and thus are not candidate for page out during memory shortages
- Large pages also improve the process of memory pre-fetching by eliminating the need to restart pre-fetch operation at 4K boundaries
- Transparent HugePages benchmarks results showing remarkable improvment
Cons:
- Huge Pages require upfront reservation. System Admin is required to set kernel tunable to desired number of HugePages: vm.nr_hugepages=<number_of_pages>
- Linux Transparent Huge Pages (THP) feature does not have upfront cost. THP is still new and has limited uses and known performance bugs. More THP testing is needed!
- Application should be HugePage aware. For example: java application should be started with "-XX=+UseLargePages" option in order to use large pages for java heap. Otherwise, pages allocated may not be used for any purpose. One can monitor Huge Page usage using "cat /proc/meminfo|grep PageTables"
- HugePages require contiguous physical memory of sizes: 2 MB and 1GB. Request for large pages may fail if the system is running for a longer period and most of the memory is demoted to 4 KB chunks.
But because, significantly, a growing number of of our daily life gets associated with the net, the quantity of information kept online expands rapidly and this raises a concern regarding the dependability of the cloud storage space.
ReplyDeletecloud review from joe
Amazing Article, thank you!. I just wish to give you a big thumbs up for the excellent post. Kindly keep updating your blog. Java Developer is a dream career for IT students.To start wonderful Career to become a Java developer learn from Java Training in Chennai. or learn thru Java Online Training from India .
ReplyDeleteor Javascript Training in Chennai. Nowadays JavaScript has tons of job opportunities on various vertical industry.
Thanks for the command of this topic, thanks to that I got here. Cool thing.
ReplyDeleteJune
Superb. I really enjoyed very much with this article here. Really it is an amazing article I had ever read. I hope it will help a lot for all. Thank you so much for this amazing posts and please keep update like this excellent article. thank you for sharing such a great blog with us.
ReplyDeletemicrosoft azure training in bangalore
rpa training in bangalore
rpa training in pune
best rpa training in bangalore
Crypto-currency as a modern form of the digital asset has received a worldwide acclaim for easy and faster financial transactions and its awareness among people have allowed them to take more interest in the field thus opening up new and advanced ways of making payments. Crypto.com Referral Code with the growing demand of this global phenomenon more,new traders and business owners are now willing to invest in this currency platform despite its fluctuating prices however it is quite difficult to choose the best one when the market is full. In the list of crypto-currencies bit-coins is one of the oldest and more popular Crypto.com Referral Code for the last few years. It is basically used for trading goods and services and has become the part of the so-called computerized block-chain system allowing anyone to use it thus increasing the craze among the public, Crypto.com Referral Code.
ReplyDeleteCommon people who are willing to purchase BTC can use an online wallet system for buying them safely in exchange of cash or credit cards and in a comfortable way from the thousands of BTC foundations around the world and keep them as assets for the future. Due to its popularity, many corporate investors are now accepting them as cross-border payments and the rise is unstoppable. With the advent of the internet and mobile devices,information gathering has become quite easy as a result the BTC financial transactions are accessible and its price is set in accordance with people’s choice and preferences thus leading to a profitable investment with Crypto.com Referral Code Code. Recent surveys have also proved that instability is good for BTC exchange as if there is instability and political unrest in the country due to which banks suffer then investing in BTC can surely be a better option. Again bit-coin transaction fees are pretty cheaper and a more convenient technology for making contracts thus attracting the crowd. The BTC can also be converted into different fiat currencies and is used for trading of securities, for land titles, document stamping, public rewards and vice versa.
Another advanced block-chain project is Ethereumor the ETH which has served much more than just a digital form of crypto-currency Crypto.com Referral Code and its popularity in the last few decades have allowed billions of people to hold wallets for them. With the ease of the online world,the ETH have allowed the retailers and business organizations to accept them for trading purposes, therefore, can serve as the future of the financial system.
Our full Lace Front Wigs are all hand made with a lace cap. They are manufactured with thin lace sewn on top of the cap. Individual hairs are then sewn onto the thin lace. Each lace wig has lace all around the unit which will need to be cut prior to securing the wig to your head. You will need to cut along the hairline around your entire head. By doing so, you will be able to wear your hair anyway you like. You can even style ponytails, up-dos, etc. Once the Lace Wigs is successfully applied, it will appear that all the hair is growing directly from your head!
ReplyDeleteLace front wigs are hand-made with lace front cap & machine weft at back. Lace front wigs are manufactured with a thin lace that extends from ear to ear across the hairline. When you receive the wig, the lace will be quite long in the front. Cut and style according to your preference, as you will need to apply adhesive along the front of the wig. Once the wig is applied, you will still have Lace Wigs with a very natural appearance.
TeamWigz Provide the Best Lace Front Wigs and Lace Wigs in Johannesburg and South Africa.
Purchase EMAIL LEADS
ReplyDeleteOn the off chance that your organization is in the post for speculators or new business tries, business opportunity leads give you data of those needing to begin a business. They are an email away from being a purchaser or your business partner.Time is of the quintessence in each advertising methodology. purchase email lists Regular postal mail, for instance, takes an all-inclusive time from the mission time frame to usage. Not everything organizations can bear to invest such measure of energy to get advertising results. This might be one reason why email showcasing got famous. On account of modernization and high innovation, with your email contact show, you can reach and pass on your message to a huge number of individuals with only a couple clicks away.
Tongkat Ali ist eine Pflanze beheimatet in Südostasien. Sie gehört zur Gattung der Bittereschengewächse und Ihr botanischer Name lautet “Eurycoma longifolia”.
ReplyDeleteMaca Kapseln Es gibt noch eine weitere Reihe länderspezifischer Namen
wie z. B. “Pasak Bumi”, wie die Pflanze in Indonesien genannt wird oder “longjack”, die allgemeine Bezeichnung für Tongkat Ali Kaufen in den USA, Kanada und Australien.
Das Ursprungsland von Tongkat Ali Kaufen ist Indonesien, daher findet man auch dort auch die größten Bestände. Weitere Vorkommen gibt es in Ländern wie Thailand, Malaysia, Vietnam und Laos.
Die Einnahme von Tongkat Ali Kaufen empfiehlt sich insbesondere für Leistungssportler, die einen schnellen
Muskelaufbau und Muskelzuwachs anstreben und nicht auf illegale und künstliche Substanzen zurückgreifen möchten um Ihren Testosteronspiegel zu erhöhen.
Generell empfiehlt sich eine Einnahme von Tongkat Ali für alle Männer ab dem 30ten Lebensjahr, da in dieser Phase nachweislich die Produktion von körpereigenem Testosteron zurückgeht. Dies macht sich vor allem dadurch bemerkbar dass die körperliche Leistungsfähigkeit nachlässt, die Lust auf Sex spürbar abnimmt und dadurch allgemein das Selbstwertgefühl negativ beeinflusst wird.
Mit der Einnahme von Tongkat Ali können Sie nachweislich Ihre Libido steigern, Ihr Testosteron erhöhen und Ihre gewohnte Lebensenergie aus den jungen Jahren Ihres Lebens wieder herbeiführen. Hier können Sie übrigens weitere Informationen bekommen zum Thema ‘Libido steigern‘ ganz natürlich. Sollten Sie daran interessiert sein lohnt es sich auch unseren Artikel über Butea Superba zu lesen.
Tongkat Ali wächst als Strauch und kann Höhen von bis zu 12 Metern erreichen. Typischerweise dauert es 10-15 Jahre bis solche Ausmaße erreicht werden. Der Strauch trägt anfangs grüne Blüten die sich im Laufe der Zeit, bis zur Reife, rot färben.
Allerdings sind die Blüten im Hinblick auf die Wirkung der Pflanze weniger interessant. Der wertvolle Teil verbirgt sich unter der Erde.
Im Laufe der Jahre wachsen die Wurzeln teilweise senkrecht und bis zu mehrere Meter tief in den Boden, was die Ernte zu einer schweren und mühsamen Arbeit werden lässt. Je älter die Wurzeln sind, desto höher ist auch die Anzahl der Wirkstoffe Butea Superba.
Von daher gilt es einige Dinge zu beachten sollten Sie Tongkat Ali kaufen wollen.
Testimonial Review of Taskade, Taskade Testimonials the all-in-one collaboration platform for remote teams. Unleash your team productivity with task lists, mindmaps, and video chat.
ReplyDeleteHealth Experts have proven that regular exercise coupled with a good diet allow you to live longer and healthier. In this busy day and age, not everyone has the time to go to the gym - resulting to a lot of overweight people that desperately need to exercise. A healthy alternative is for you to Buy Home Gym Equipments that you can store in your own home or even at your office. Here are some tips when buying home gym equipment.
ReplyDeleteFirst, know your fitness goals and keep these goals in mind when you are buying home gym equipment. One of the biggest mistakes that people make is buying the biggest or trendiest fitness machine simply because they like how it looks. More often than not, these end up gathering dust in your storage rooms or garage because you never end up using them. It is important to take note of what particular type of physical activity you want or enjoy doing before you buy your exercise machine. If you are looking to loose a few pounds and you enjoy walking or hiking, a treadmill is the best option for you. If you are looking to tone your lower body while burning calories a stationary bike is your obvious choice. Similarly, Special Equipments for Core Strength Exercises, Strength Training Weight Vests, Core Strength & Abdominal Trainers, Home Cardio Training, Strength Training Power Cages, Strength Training Racks & More.
Second, set aside a budget before Buying Home Gym Equipments. Quality exercise machines do not come cheap. They are constantly exposed to wear and tear when they are used properly. So, pick machines that are built to last and have passed quality certifications to get the most out of your money. If you are operating on a tight budget, think about investing in several weights, We can Provide you High Quality Home Gym Equipments at Very Low Prices for your Complete Uses: Core Strength Exercises, Strength Training Weight Vests, Core Strength & Abdominal Trainers, Home Cardio Training, Strength Training Power Cages, Strength Training Racks & More.
Its the Right Time to Buy Home Gym Equipments for you at Very Low Prices.
- Como organizar sua Semana com o Taskade - Segunda Feira, primeiro dia.
ReplyDelete- Como organizar sua semana com o Taskade - Terça - Vlog de Produtividade
- Como organizar sua semana com o Taskade - Quarta
- Como organizar sua semana com o Taskade - Quinta - Vlog Produtividade.
Taskade - Sexta, Sábado e Domingo. Como foi e uma grande novidade
Impresión online en gran formato, Impresión vinilos imprimimos roll ups, photocalls, vinilos, lonas. Envío gratis
ReplyDeleteWe are a clean skincare brand, 100% organic and made with what the earth has given us first. Our product formulations came from listening to our ingredients. From their benefits, scents and results, our products are truly science of the earth. https://www.bakespace.com/members/profile/firstbaseskncare/1027840/ We wanted to step back from the long list of hard to pronounce scientific gibberish and provide ingredients relatable and understood. We are very proud to be one of the first few on the market to be ECO-Certified under the COSMOS standards, and for us we want to leave the earth better than we found it.
ReplyDeleteAre Anabolic Steroids and Body Building Supplements Safe to Use?
ReplyDeleteAnabolic steroids and lifting weights supplements are a questionable way that numerous competitors and jocks to construct muscle. Frequently alluded to as these steroids, these enhancements are introduced in both regular and engineered structures. Heaps of the debate concerns the engineered structure because of the destructive results that weight lifters can experience the ill effects of. Characteristic anabolic enhancements will in general be less destructive whenever utilized with some restraint. In any case, Hilma biocare Anabolic steroids advance cell development and division, which is the regular standard behind weight training since it causes enormous muscles framed from more modest ones.
Lifting weights Supplements have been demonized by a standing for an assortment of reasons. At the point when competitors and maltreatment of anabolic steroids muscle heads, they acquire an upper hand over their rivals. Thus, authorities in the game of cricket to weight training thought about anabolic steroids and enhancements contrary to the guidelines. This is apparent in the new outrages identified with baseball whizzes like Barry Bonds and Mark McGwire. During the 1980s, the World Wrestling Federation additionally experienced a major embarrassment that prompted the utilization of anabolic steroids and enhancements in the news. These and different outrages have added to the helpless standing of these questionable anabolic enhancements.
Training on the impacts of anabolic steroids and enhancements is important to help direct individuals from them. Sadly, large numbers of the competitors in secondary school have gone to anabolic enhancements to help them acquire an upper hand against their rivals. With the constructive outcomes that are depicted by proficient competitors, more youthful clients are regularly unconscious of the ramifications as long as possible. Numerous anabolic steroids supplement clients experience the ill effects of hypertension, which can prompt a lot of genuine ramifications and can't be fixed on the body of the client.
Despite the fact that steroids identical to a lot of debate, it isn't liberated from results positive. In the event that you need to assemble muscle quick, anabolic steroids and enhancements is one approach to do as such. They were additionally utilized in an assortment of clinical medicines until it was restricted in 1988. Pediatricians utilized anabolic to invigorate development in kids with hindered development chemical. Specialists likewise have utilized steroids to help malignancy and AIDS patients increment their hunger and fabricate bulk. Up to this point, specialists additionally used to prompt pubescence in young men. Presently, clinical medicines use testosterone for this reason and to assist competitors with recuperating wounds.
Enhancements of manufactured steroids are dubious on the grounds that they give expanded strength and bulk, yet at extraordinary expense to the wellbeing of the client. The normal way, in any case, might be less hurtful. Regardless, even common anabolic maltreatment can be inconvenient to their wellbeing and bodies. By and large, can be the master or mentor to exhort you and assist you with finding the most valuable type of lifting weights material to assist you with accomplishing the best outcomes.
Buy Modafinil Online – Buying pills like Modafinil is not easy. Are you trying to purchase modafinil online? If your answer is Yes, then you are in the right place. In this buyer’s guide, we are going to cover everything you need to know about the most popular nootropic in the world.
ReplyDeleteHealth Experts have proven that regular exercise coupled with a good diet allow you to live longer and healthier. In this busy day and age, not everyone has the time to go to the gym - resulting to a lot of overweight people that desperately need to exercise. A healthy alternative is for you to Buy Home Gym Equipments that you can store in your own home or even at your office. Here are some tips when buying home gym equipment.
ReplyDeleteFirst, know your fitness goals and keep these goals in mind when you are buying home gym equipment. One of the biggest mistakes that people make is buying the biggest or trendiest fitness machine simply because they like how it looks. More often than not, these end up gathering dust in your storage rooms or garage because you never end up using them. It is important to take note of what particular type of physical activity you want or enjoy doing before you buy your exercise machine. If you are looking to loose a few pounds and you enjoy walking or hiking, a treadmill is the best option for you. If you are looking to tone your lower body while burning calories a stationary bike is your obvious choice. Similarly, Special Equipments for Core Strength Exercises, Strength Training Weight Vests, Core Strength & Abdominal Trainers, Home Cardio Training, Strength Training Power Cages, Strength Training Racks & More.
Second, set aside a budget before Buying Home Gym Equipments. Quality exercise machines do not come cheap. They are constantly exposed to wear and tear when they are used properly. So, pick machines that are built to last and have passed quality certifications to get the most out of your money. If you are operating on a tight budget, think about investing in several weights, We can Provide you High Quality Home Gym Equipment at Very Low Prices for your Complete Uses: Core Strength Exercises, Strength Training Weight Vests, Core Strength & Abdominal Trainers, Home Cardio Training, Strength Training Power Cages, Strength Training Racks & More.
Its the Right Time to Buy Home Gym Equipment for you at Very Low Prices.
국내 최고 스포츠 토토, 바카라, 우리카지노, 바이너리 옵션 등 검증완료된 메이져 온라인게임 사이트 추천해 드립니다. 공식인증업체, 먹튀 검증 완료된 오라인 사이트만 한 곳에 모아 추천해 드립니다 - 카지노 사이트 - 바카라 사이트 - 안전 놀이터 - 사설 토토 - 카지노 솔루션.
ReplyDelete온라인 카지노, 바카라, 스포츠 토토, 바이너리 옵션 등 온라인 게임의 최신 정보를 제공해 드립니다.
탑 카지노 게임즈에서는 이용자 분들의 안전한 이용을 약속드리며 100% 신뢰할 수 있고 엄선된 바카라, 스포츠 토토, 온라인 카지노, 바이너리 옵션 게임 사이트 만을 추천해 드립니다.
It's always helpful to read through content from 토토사이트
ReplyDeleteother authors and practice something from other sites.
토토사이트 What's up, of course this article is really pleasant and
ReplyDeleteI have learned lot of things from it concerning blogging.
thanks.
It's an awesome article for all the online
ReplyDeletepeople; 카지노사이트
they will obtain benefit from it I am sure.
카지노사이트 Incredible points. Sound arguments. Keep up the great effort.
ReplyDeleteOferecemos os melhores serviços para seguidores, curtidas, comentários e visualizações no Instagram. Os serviços são entregues de forma rápida, segura e por um preço honesto e barato.
ReplyDeleteTodos os serviços são iniciados de forma automática e você pode fazer um teste grátis de seguidores, curtidas e visualizações no Instagram.
O Go Followers surgiu em 2015 e durante alguns anos foi o melhor e maior site para comprar seguidores, curtidas e comentários no instagram. Com o passar dos anos evoluímos e em 2021 lançamos um novo site simples e intuitivo para aumentar a experiência dos mais de 150.000 clientes atendidos.
Nossa ferramenta envia seguidores brasileiros reais e ativos em sua grande maioria para qualquer perfil do Instagram. Escolha o melhor pacote para comprar seguidores instagram de alta qualidade. Você poderá escolher alguns pacotes como seguidores com curtidas, seguidores masculinos, seguidores femininos e seguidores automáticos.
Todos os pedidos são feitos de forma automática e iniciam em poucos minutos após a compra, tá esperando o que?
Life before legitimization made them call our nearby seller and hanging tight for 45 minutes in a 7-11 parking garage. Presently, with mail request cannabis administrations accessible at the dash of a catch, we need to separate the absolute best in contrast with weed available to be purchased . weed for sale
ReplyDeleteHave you at any point seen that gigantic cannabis dispensaries will in general cheat you? We have. Those organizations treat pot as "green gold" and expect to fill their pockets while you're paying twice as much for their items. buy weed online The present the day to quit shopping on their standing. Purchase Dank Now is a legitimate weed online store that makes something
ReplyDeleteDankwoods Flavors We need to concede, whoever made the names for Dankwoods did as such with some genuine ability. Tragically, the actual item has been demonstrated to be noteworthy. dank woods The general purpose of these Dankwoods Flavors are to inspire expected purchasers, it's splendid promoting that aided mix the bearing for pre moves in the lawful cannabis market. A quarter gram of concentrate is evidently inside as indicated by the mark.
ReplyDeletethanks for this informative article about linux in cloud and how to manage memory.its very useful and in a detailed manner.Angular training in Chennai
ReplyDeleteGaruda999 adalah sebuah agen casino online yang merupakan mitra salah satu bandar judi online24jam internasional terbesar di Asia, SBobet, yang berpusat di Filipina. Sebagai salah satu mitra penyedia layanan judi online terbesar, tentunya kami juga berkomitmen untuk memberikan layanan terbaik bagi pengguna kami, yaitu penggemar judi online Indonesia. judi slot game, slot online nexus, slot online casino, slot online 88, slot online idn, bandar togel idn, judi bola pulsa, casino online terbesar di dunia, bandar togel pasaran terbaik, judi bola 777, situs judi bola yang ada promo bonus 100, judi bola 828, casino online game, judi bola depo pulsa, situs judi bola freebet, situs judi online poker yang banyak bonus, judi online live, judi poker deposit pakai pulsa 5000 Dengan adanya aturan yang berlaku di Indonesia, kami menyadari jika banyak penggemar judi online di Indonesia, yang kesulitan untuk mendapatkan layanan yang berkualitas. Sehingga untuk itulah kami, Garuda 999 hadir sebagai agen casino yang terpercaya, untuk melayani penggemar judi online di Indonesia, tanpa bertentangan dengan aturan yang berlaku. Karena sebagai mitra yang mematuhi aturan, kami beroperasi dari Manila, Filipina, sebagaimana mitra induk kami. Dengan demkian penggemar judi online di Indonesia, dapat dengan mudah mengakses layanan judi online, yang kami sediakan dan merasakan kesenangan bermain judi online dengan aman dan nyaman, selayaknya bermain pada casino online bertaraf internasional. judi bola aman, Judi Slot terlengkap, master judi bola 99, qq slot online freebet,judi online poker sampoerna, slot online indonesia terpercaya, slot online game, situs judi bola eropa, bandar togel kamboja, judi bola 168, slot online judi, peraturan judi bola 90 menit, 9 poker, casino online paypal, judi bola deposit pulsa, judi bola adalah casino online di indonesia, bandar togel tertua dan aman, casino online malaysia, judi bola mix parlay, bandar, togel onlen, casino online terbaru. Sebagai agen casino online mitra dari SBobet, yang merupakan salah satu agen bola Euro2021 terbesar di Asia, tentunya Garuda 999 juga membuka peluang bagi penggemar taruhan olah raga khususnya sepak bola, di tanah air, untuk ikut meramaikan even sepak bola dunia tersebut. Dengan didukung oleh sistem sports book handal yang disediakan oleh SBobet, penggemar taruhan sepak bola di Indonesia - Judi Online, tidak perlu khawatir untuk ketinggalan bertaruh pada even besar tersebut. Karena sistem sports book yang kami adopsi dari mitra induk kami, merupakan salah satu yang terbaik di dunia, yang dapat melayani taruhan sesuai jadwal pertandingan pada Euro 2021 secara real time - Judi Slot.
ReplyDeleteBuy our cannabis concentrates on-line and develop ordering dabs online future at our Turners Falls clinic. bound concentrates like dabs are often consumed on their own; others, like kief, will simply be read Our Menu of Concentrates & Order on-line.
ReplyDeleteOb Schmutz, hartnäckiger Belag, Schimmel, Vogelkot, Bakterien, Dreck, Staub oder unangenehme Gerüche, bei unserer Gebäudereinigung Hannover erwartet Sie ein glänzendes Ergebnis. Die Firma Immoclean reinigt Gebäude unterschiedlichster Art wie Schulen, Kindergarten, Arztpraxis, Altersheim, Museum, Disko, Hallen, Krankenhaus, Hotel, Baustelle, Restaurant, Kaufhaus, Supermarkt - Unterhaltungsreinigung Hannover.
ReplyDeleteVertrauen Sie dabei unserer Erfahrung, den vielen Referenzen und einer Kundenzufriedenheitsgarantie. Zuverlässigkeit und Qualität sowie eine absolut hygienische Reinigung können wir Dank unseren geschulten und mit modernstem Reinigungsequipment ausgestatteten Mitarbeitern gewährleisten - Broreinigung Hannover. In einer umfassenden und persönlichen Beratung erstellen wir sowohl für Klein- als auch Großkunden einen persönlichen Reinigungsplan ganz nach Ihren Wünschen. Bei Immoclean aus Hannover, der Nummer 1 unter den Reinigungsdiensten, Gebudereinigung hannover ist Ihre Firma oder Unternehmen in guten Händen. Vereinbaren Sie noch heute einen Termin mit unserem Reinigungsunternehmen, wir freuen sich auf Sie - Praxisreinigung Hannover!
바카라사이트 Awesome post. I’m a regular visitor of your site and appreciate you taking the time to maintain the excellent site. I will be a regular visitor for a long time.
ReplyDelete바카라사이트 You can certainly see your expertise in the work you write. The world hopes for even more passionate writers like you who aren’t afraid to say how they believe. Always follow your heart.
ReplyDelete토토사이트 Great post. I was checking constantly this blog and I’m impressed! Extremely useful info specially the last part �� I care for such info a lot. I was seeking this certain information for a long time. Thank you and best of luck.
ReplyDeleteCan I simply just say what a comfort to find an individual who truly understands what they’re talking about on the net. You definitely realize how to bring a problem to light and make it important. More and more people have to look at this and understand this side of your story. It’s surprising you’re not more popular given that you most certainly have the gift.
ReplyDelete국내경마
magosucowep
CellSpike Specializes in producing the best Research Peptides, Research Liquids, Pinnacle Peptides, Peptide Sciences, Paradigm Peptides, cjc-1295,bpc-157, tb-500 ipamorelin, Rad140, ostarine, gw501516, yk-11, s-4 and Sarms on the market. We pride ourselves with the highest quality products, the fastest shipping, and the absolute best customer service. Order with confidence! Our professional staff is here to help bring you the most innovative Research Peptides and Sarms guaranteed. CellSpike is proud to be an American-owned small business providing loyal customers with the highest quality products and service.
ReplyDeleteWith higher purity than many other suppliers, CellSpike products are your #1 source for Research Peptides and Research SARMs. At CellSpike, we offer one-day processing and shipping for all orders placed Monday through Friday. We also guarantee safe packaging and proper storage in controlled environments during processing.
CellSpike is dedicated to ensuring every one of our customers enjoys the best in service and product quality. If you have any questions or concerns, our team is always available to help you out!
Check out today’s coronavirus live update, the availability of the nearest hospital ICU bed, and the ambulance contact number in Covid Surokkha. Visit: ambulance service dhaka
ReplyDeleteDiseñamos la página web para que tu empresa tenga una imagen digital profesional 24/7 y sea más fácil que te ubiquen online, puedan conocer tu oferta de productos, servicios, que logren contactarte de una forma más rápida y fácil.
ReplyDeleteNuestras páginas web son visualmente atractivas, tienen un diseño web responsive para ser visualizadas en un dispositivo móvil, lo que permite una experiencia de usuario agradable, intuitiva, simple, rápida y con usabilidad. Están optimizadas al SEO para ser leídas con facilidad por los motores de búsqueda como Google y ayudar al posicionamiento de tu contenido con las palabras clave con las que deseas darte a conocer.
Al tener una página web de calidad te diferenciarás de la competencia al posicionarte en comparación con los que no tienen presencia digital, además de que atraer mayor tráfico a tu sitio web y permitirte mayor exposición que puede verse traducida en convertir a los visitantes en clientes e incrementar tus ventas. posicionamiento web madrid
Bright Achievements has been proven to be effective in successfully treating children with ABA Therapy NJ for Children with Autism. ABA Therapy in New Jersey Combined with the expert care and guidance of our trained BCBA/LBAs and therapists, your child can achieve more than you thought possible.
ReplyDeleteBecause of its methods of behavior identification and modification, ABA therapy in New Jersey has been proven to be effective in successfully treating children with ASD. Combined with the expert care and guidance of our trained BCBA/LBAs and therapists, your child can achieve more than you thought possible.
We are Top in-home Autism Therapy Provider in New Jersey, providing ABA therapy to children with autism & their families in New Jersey. Autism Therapy NJ
Offering Comprehensive Digital Marketing Services To Businesses Looking To Improve Their Online Presence marketing agencies philadelphia
ReplyDeleteเว็บแทงบอล แทงบอลออนไลน์ สมัครแทงบอล ที่คนเล่นเยอะที่สุด ค่าคอม 0.5% แทงขั้นต่ำ 10 บาท UFA169
ReplyDeleteIm Immo Cashflow Booster erfahren Sie, wie Sie durch smarte Immobilienanlagestrategien passiven Cashflow generieren. Sie müssen keine Bankgeschäfte tätigen, Geld leihen oder etwas kaufen.
ReplyDeleteEric erklärte 6 verschiedene Strategien, die verwendet werden können, um durch Leasing und Leasing einen Cashflow zu generieren. Diese Methode ist völlig neu und eigentlich eine interne Strategie.
Anfangs war ich dieser Strategie etwas skeptisch gegenüber, denn wenn man die vermietete Wohnung wieder untervermieten möchte, wie überzeugt man dann den Vermieter.
Aber ich habe eine bessere Ausbildung und Eric hat klare Anweisungen, wie man den Vermieter leicht überreden kann. Der Immo Cashflow Booster bietet dir Top aktuelle Strategien, welche auch jahrelang funktionieren. Und in diesem Erfahrungsbericht, werde ich dir meine persönlichen Immo Cashflow Booster Erfahrungen mitteilen.
Just 99 Web Design offers affordable web design packages for every business, from basic one-page websites to full eCommerce website design services. affordable ecommerce website design
ReplyDeleteAvantajlý ve kaliteli bir dünyaya Superbetin ile giriþ yapýn. süperbetin global ölçekte bahis ve casino hizmet veren bir þirkettir. Kullanýcýlar kaliteli bir hizmet sunmakta. Bahsedeceklerimizden ziyade sizlerde Superbetin giriþ yaparak hizmetleri görebilirsiniz. Makalemizde sizlere Superbetin güvenilir mi? Süperbetin giriþ bilgileri gibi konularda bahsedeceðiz. Ayrýca Superbetin kayýt ol sayesinde özel bonuslara ulaþýn. Sizlerde süperbetin sayesinde avantajlý bir bahis ve casino hizmeti ulaþýn.
ReplyDeleteSüperbetin sunduðu hizmetler hakkýnda detaylý bilgiler vereceðiz. Lakin öncelikle sitenin güvenilirliðinden bahsedelim. Ýlk olarak güvenilir olmayan bir site sektörde uzun yýllar hizmet veremez. Dolandýrýcý siteler zaten en fazla 3 ay hizmet verebilmiþtir. Superbetin ise sektörde 10 yýlý aþkýn zamandýr hizmet vermekte. Lisansýný bahis ve casino sektörünün en göze lisans kurumu olan çuraçao hükümetinden almýþtýr. Superbetin oyunlarý bahis ve casino oyunlarýndan saðladýklarý kazançlarýný sorun yaþamadan çekebilmekte.
Superbetin
Süperbetin giriþ yaparak sizlerde avantajlý bir bahis ve casino hizmetine ulaþabilirsiniz. Türkiye’deki kullanýcýlar güncel giriþ adresine sayfamýzda her zaman ulaþabilmekte. Avantajlý bir bahis ve casino hizmetine doðru siteyi tercih ederek ulaþýn. Hesabý olmayan kullanýcýlar Süperbetin kayýt iþlemini kolay bir þekilde yapabilmekte. Hiçbir ek belge göndermeden ve ayrýca kimlik bilgisi vermeden kolay bir þekilde hesabýnýzý oluþturun. Ayrýca yeni üyelere özel bonuslar bulunmakta. Deneme bonusu ve hoþgeldin bonusu yeni üyelere özeldir.
Süperbetin bahis bölümünde geniþ bir bahis bülteni canlý olarak iddaa oynayabilirsiniz. Ayrýca tek maç üzerinden canlý bahisler oynanabilmekte. Binlere farklý müsabakaya yüksek oranlardan canlý bahis oynayabileceðiniz bir hizmet sizleri beklemekte. Sadece spor bahisleri de deðil. E-sports bahisleri, sanal bahisleri gibi farklý bahis seçenekleri de bulunmakta.
Superbetin sayesinde gerçek bir casino hizmetine de ulaþabilirsiniz. Gerçek casino salonlarýndan canlý kurpiyerlerin sunumlarýyla 4K görüntü kalitesi üzerinden hizmet alýn. Canlý casino oyunlarý ve binlerce farklý slot oyunlarý sizleri beklemekte.
Süperbetin bahis ve casino oyunlarýndan saðladýðýnýz kazançlarýnýzý sorun yaþamadan çekebilirsiniz. Sonuç olarak istediðiniz finansal yöntem üzerinden para yatýrma ve çekme iþlemlerinizi kolay bir þekilde yapýn.
Sizlerde Süperbetin giriþ yaparak avantajlý bahis ve casino dünyasýna giriþ yapabilirsiniz.
Süperbetin kullanýcýlarý para yatýrma ve çekme iþlemlerinizi yapabilirsiniz. Sonuç olarak BTC, usdt gibi coinler üzerinden finansal iþlem sunan sitelerden birisidir.
Geniþ bir iddaa bülteni üzerinden binlerce farklý müsabakaya ayrýca yüksek oranlardan canlý iddaa oynayýn.
Gerçek casino salonlarýndan özel olarak bir hizmete ulaþýn. Canlý casino oyunlarý ve slot oyunlarý superbetin dünyasýnda sizleri beklemekte.
Ýnternet üzerinden gerçek bir casino hizmetine ulaþabilirsiniz. Gerçek casino salonlarýndan canlý casino hizmeti veren özel siteleri bulunmakta. Canlý casino siteleri gerçek casino salonlarýndan kullanýcýlarýna gerçek paralar üzerinden casino oyunlarý sunmakta canlı casino. Oyuncular internete baðlý olduklarý her yerden casino oyunlarý oynayabilmekte. Lakin bahsettiðimiz ve bahsedeceðimiz hizmetleri almak için doðru casino siteleri seçmeniz gerekmekte. Doðru siteleri yani güvenilir casino siteleri tercih ederek hem gerçek bir hizmet alýn hem de kazançlarýnýzý sorunsuz bir þekilde çekin.
ReplyDeleteSektörün en gözde casino þirketleri sayfamýzda paylaþýlmakta. Casino siteleri giriþ butonlarý üzerinden sitelere ulaþabilirsiniz. Sizlere sitelerin hizmetleri hakkýnda bilgiler vereceðiz. Sitelerin sunduklarý hizmetleri, bonuslarý ve finansal araçlarý hakkýnda bilgileri sizlere sunacaðýnýz. En iyi canlı casino sayfamýzdan ulaþabilirsiniz.
Canlý casino
Paylaþtýðýmýz siteler oyuncularýna gerçek casino salonlarýndan hizmet sunmakta. Oyuncular BlackJack, rulet, poker gibi casino masa oyunlarýný 4K görüntü kalitesi üzerinden gerçek casino salonlarýndan oynamakta. Ayrýca masa oyunlarý yanýnda özel oyunlarda bulunmakta. Canlý olarak sunulan oyunlar 4K görüntü kalitesi üzerinden oyunculara aktarýlmakta. Oyunlarýn sunumlarý canlý kurpiyerlerin sunumlarýyla yapýlmakta. Canlý casino oyunlarý kurpiyerlerin sunumlarýyla oynanmakta. Ayrýca masalarda bulunan herkes sizler gibi gerçek oyuncudur. Asla sitelerde bot hesaplarý bulunmaz. Herkes gerçek oyuncudur. Ayrýca odalarda sohbet bölümleri bulunmakta. Canlý casino
oyunlarý oynanýrken ayný zamanda diðer oyuncular ile sohbet edebilirsiniz.
Sitelerde poker, blackjack, rulet gibi onlarca farklý casino masa oyunlarý. Özel olarak hazýrlanan crayz time gibi canlý casino oyunlarý. Aviator, zeplin gibi popüler oyunlar ve binlerce farklý slot oyunlarý bulunmakta. Oyuncular istedikleri oyunlarý istedikleri bet üzerinden oynayabilmekte. Casino siteleri gerçek kumarhanelerdeki oyunlarý ve hatta daha fazlasýný kullanýcýlarýna sunmakta canlı casino.
Lakin unutmayýn bahsettiðimiz hizmetleri en iyi casino siteleri için geçerli. Her canlý casino sitesi ayný hizmeti vermemekte. Bundan dolayý önünüze gelen her casino sitesi giriþ yapmayýn. Güvenilir casino siteleri giriþ yaparak gerçek bir hizmete ulaþýn.
Oyuncular casino oyunlarýndan saðladýklarý kazançlarýný sorun yaþamadan çekebilmekte. Ayrýca istedikleri finansal yöntemi kullanarak seçebilmekte. Siteler oyuncular onlarca farklý finansal araç sunmakta. Kullanýcýlar istedikleri yöntemleri kullanarak para yatýrma ve çekme iþlemlerini kolay bir þekilde canlı casino yapabilmekte.
Casino siteleri onlarca farklý bonus da vermekte. Yeni kayýt olan kullanýcýlar deneme bonusu ve free spin alarak bedava casino oyunlarý oynama fýrsatý yakalamakta. Ýlk yatýrýmlarýna özel casino hoþgeldin bonusu. Her yatýrýmlarýna özel casino yatýrým bonusu. Þansýz günlerinde ise casino kayýp bonusu alabilmekte. Ayrýca bahsettiðimiz bonuslar dýþýnda farklý casino bonuslarý da bulunmakta canlı casino.
Deneme bonusu veren casino siteleri sayesinde kayýt olarak yatýrým yapamadan bedava casino oyunlarý oynayabilirsiniz. Siteler yeni üyelerine özel olarak bedava bonus vermekte.
Bonusu alan kullanýcýlar bedava bir þekilde casino oyunlarý oynayarak ayrýca kazançlarýnýzý çekebilirsiniz.
Güvenilir canlý casino siteleri sayesinde avantajlý bir hizmete ulaþýn.
태백콜걸마사지
ReplyDelete김천콜걸마사지
문경콜걸마사지
상주콜걸마사지
안동콜걸마사지
영천콜걸마사지
영주콜걸마사지
강릉 출장샵
ReplyDelete원주 출장샵
동해 출장샵
연천 출장샵
Awesome Post.
ReplyDeletealso, Join Linux classes in Pune
KEYTOTO merupakan platform togel online 4D resmi tahun 2026 yang dirancang untuk memberikan pengalaman bermain yang lengkap, aman, dan terpercaya bagi para penggunanya. Situs ini menghadirkan berbagai pilihan pasaran togel terlengkap dari berbagai negara, sehingga pemain memiliki banyak opsi untuk memasang angka sesuai dengan preferensi mereka. Dengan sistem yang modern dan terus diperbarui, KEYTOTO memastikan setiap proses taruhan berjalan secara cepat, akurat, dan transparan.
ReplyDeleteSelain menawarkan variasi pasaran yang luas, KEYTOTO juga dikenal dengan link akses yang stabil dan terpercaya, memudahkan pengguna untuk login kapan saja tanpa hambatan. Hal ini sangat penting untuk menjaga kenyamanan pemain, terutama saat mengakses situs di waktu-waktu sibuk. Tampilan platform yang sederhana dan ramah pengguna memungkinkan baik pemula maupun pemain berpengalaman untuk menavigasi fitur dengan mudah tanpa kebingungan.
Dari sisi keamanan, KEYTOTO mengutamakan perlindungan data pribadi dan transaksi finansial dengan sistem enkripsi yang canggih, sehingga setiap aktivitas pengguna tetap terjaga kerahasiaannya. Proses pendaftaran juga dibuat cepat dan praktis, memungkinkan siapa saja untuk segera bergabung dan mulai bermain dalam hitungan menit. Selain itu, layanan dukungan pelanggan tersedia untuk membantu menjawab pertanyaan atau menyelesaikan kendala yang mungkin dihadapi pengguna.
Dengan kombinasi fitur lengkap, akses mudah, serta komitmen terhadap keamanan dan kenyamanan, KEYTOTO menjadi pilihan ideal bagi para pecinta togel online yang mencari platform terpercaya untuk bermain. toto togel
Accelerate your career with IntelliMindz training programs in Playwright with Java, Playwright with Python, Penetration Testing, Power BI, Primavera, Prompt Engineering, Python, Python Full Stack, R Tool, and Angular. Gain hands-on experience through real-time projects, expert-led sessions, and practical learning. Build industry-relevant skills, earn certification support, and excel in today's competitive technology landscape.
ReplyDeletePlaywright with Java Training in Kolkata,
Penetration Testing Training in Kochi,
Playwright With Python Training in Kochi,
Power BI Training in Kochi,
Primavera Training in Kochi,
Prompt Engineering Online Training,
Python Training in Kochi,
Python Full Stack Training in Kochi,
R Tool Training in Kochi,
Angular Training in Kadugodi
Strengthen your technical expertise with specialized programs such as AI Training, Alteryx Training, Anaplan Training, Angular Training, ANSYS Training, Application Security Training, AutoCAD Training, AWS Training, Azure Data Factory Training, and Azure Databricks Training in Marathahalli Bangalore. These industry-focused courses are designed to provide practical knowledge, hands-on project experience, and real-world exposure across artificial intelligence, analytics, business planning, web development, engineering simulation, cybersecurity, design drafting, cloud computing, and data engineering. Led by experienced professionals, these training programs help learners develop job-ready skills, stay current with emerging technologies, and enhance their career opportunities in today’s competitive technology and engineering landscape.
ReplyDeleteAI Training in Marathahalli Bangalore,
Alteryx Training in Marathahalli Bangalore,
Anaplan Training in Marathahalli Bangalore,
Angular Training in Marathahalli Bangalore,
ANSYS Training in Marathahalli Bangalore,
Application Security Training in Marathahalli Bangalore,
AutoCAD Training in Marathahalli Bangalore,
AWS Training in Marathahalli Bangalore,
Azure Data Factory Training in Marathahalli Bangalore,
Azure Databricks Training in Marathahalli Bangalore
Embedded System Training in Erode
ReplyDeleteNetApp Storage Training in Erode
Ab Initio Training in BTM Layout Bangalore
AI Training in BTM Layout Bangalore
Alteryx Training in BTM Layout Bangalore
Anaplan Training in BTM Layout Bangalore
Angular Training in BTM Layout Bangalore
ANSYS Training in BTM Layout Bangalore
Application Security Training in BTM Layout Bangalore
AutoCAD Training in BTM Layout Bangalore Enhance your career with industry-focused training programs in Embedded Systems, NetApp Storage, Ab Initio, Artificial Intelligence, Alteryx, Anaplan, Angular, ANSYS, Application Security, and AutoCAD. These courses provide hands-on learning, real-world project experience, expert-led instruction, and certification support to help you develop practical skills. Gain expertise in high-demand technologies and tools, improve your professional capabilities, and unlock rewarding career opportunities across IT, engineering, analytics, security, and design domains.
Python Training in Noida
ReplyDeletePython Full Stack Training in Noida
R Programming Training in Noida
R Tool Training in Noida
Rebar Detailing Training in Noida
Red Hat OpenShift Training in Noida
Salesforce Developer Training in Noida
AI Training in Mumbai
Alteryx Training in Mumbai
Angular Training in Mumbai Build a successful career with industry-focused training programs covering software development, data analytics, cloud technologies, and artificial intelligence. Learn Python, Python Full Stack, R Programming, Salesforce Development, Red Hat OpenShift, Angular, Alteryx, and AI through practical sessions, real-time projects, and expert mentorship. These professional courses are designed to strengthen technical knowledge, improve hands-on experience, and prepare learners for high-demand roles in today’s competitive IT industry.
Intellimindz offers professional training in Tosca, Python, R Tool, Selenium, Tableau, and Primavera across New Zealand, Whitefield, Chennai, and Velachery. These courses provide hands-on learning through real-time projects, expert guidance, and industry-focused curricula. Learners gain practical skills, certification support, and placement assistance to build successful careers in software testing, programming, analytics, business intelligence, and project management.
ReplyDeleteTosca Training in New Zealand
Python Training in Whitefield
R Tool Training in Whitefield
Selenium Training in Whitefield
Tableau Training in Whitefield
Tosca Training in Whitefield
Primavera Training in Chennai
Python Training in Velachery
R Programming Training in Velachery
This comment has been removed by the author.
ReplyDeleteAdvance your career with specialized training programs in Mumbai designed for aspiring IT and engineering professionals. Gain expertise in MATLAB, NetSuite Functional, Pega Developer, Playwright, Playwright with Python, and Rebar Detailing. Build in-demand skills through Agile, Artificial Intelligence, Application Security, and AWS Cloud Security training. These programs offer practical learning, real-world projects, expert guidance, certification support, and career-focused development to help learners stay competitive in today’s rapidly evolving technology landscape.
ReplyDeleteMATLAB Learning Training in Mumbai
NetSuite Functional Training in Mumbai
Pega Developer Training in Mumbai
Playwright Training in Mumbai
Playwright with Python Training in Mumbai
Rebar Detailing Training in Mumbai
Agile Training in Mumbai
AI Training in Mumbai
Application Security Training in Mumbai
AWS Cloud Security Training in Mumbai
Intellimindz offers a wide range of professional training programs in Coimbatore focused on software testing, SAP modules, cloud applications, and Agile methodologies. The courses include Rest Assured Training, S4 HANA SD Training, Salesforce Training, SAP BODS, SAP BW/4HANA, SAP EWM, SAP PS, SAP SD, SAP SF Employee Central, and Scrum Master Training. These programs are designed with practical, hands-on learning and real-time project exposure to help learners build strong industry skills and become job-ready for roles in enterprise software, automation testing, and project management.
ReplyDeleteRest Assured Training in Coimbatore
S4 HANA SD Training in Coimbatore
Salesforce Training in Coimbatore
SAP BODS Training in Coimbatore
SAP BW/4HANA Training in Coimbatore
SAP EWM Training in Coimbatore
SAP PS Training in Coimbatore
SAP SD Training in Coimbatore
SAP SF Employee Central Training in Coimbatore
Scrum Master Training in Coimbatore
Penetration Testing Training in Trivandrum
ReplyDeletePlaywright with DotNet Training in Trivandrum
Playwright with CSharp Training in Trivandrum
Playwright with Java Training in Trivandrum
Primavera P6 Training in Trivandrum
Procurement Training in Trivandrum
Product Analyst Training in Trivandrum
Qlik Sense Training in Trivandrum
Quantity Surveying Training in Trivandrum
Quantum Engineering Training in Trivandrum
Penetration Testing, Playwright with DotNet, CSharp, and Java, Primavera P6, Procurement, Product Analyst, Qlik Sense, Quantity Surveying, and Quantum Engineering Training in Trivandrum at IntelliMindz deliver expert‑led, hands‑on sessions with real‑time projects. Each program builds practical skills, industry knowledge, and certification support to help learners advance careers in IT, analytics, engineering, and enterprise solutions.
Intellimindz Trichy offers career-focused training programs in Rebar Detailing, Artificial Intelligence, Application Security, AWS Cloud Security, Epicor, NetApp Storage, Oracle NetSuite, Playwright Automation, SQL, and WordPress. These courses combine theoretical knowledge with hands-on project experience, expert-led instruction, certification guidance, and placement support. Learners gain practical skills aligned with current industry requirements, enabling them to excel in technology, cybersecurity, cloud computing, enterprise applications, web development, database management, and engineering domains.
ReplyDeleteRebar Detailing Training in Trichy
Artificial Intelligence Training in Trichy
Application Security Training in Trichy
AWS Cloud Security Training in Trichy
Epicor Training in Trichy
NetApp Storage Training in Trichy
Oracle NetSuite Training in Trichy
Playwright Automation Training in Trichy
SQL Training in Trichy
WordPress Training in Trichy
Intellimindz offers industry-focused training programs in Dubai designed to help learners build strong technical and professional skills across various domains. The courses include Mendix, Red Hat OpenShift, System Administration, CATIA Automation, Clinical SAS, MATLAB, NetSuite, Pega, Playwright, and Playwright with Python. These training programs emphasize practical learning, real-time projects, and hands-on experience to help students and professionals gain expertise in low-code development, cloud platforms, enterprise applications, automation testing, engineering design, and data analytics. With expert guidance and industry-relevant curriculum, Intellimindz prepares learners for successful careers in today's technology-driven environment.
ReplyDeleteMendix Training in Dubai
Red Hat OpenShift Training in Dubai
System Admin Training in Dubai
CATIA Automation Training in Dubai
Clinical SAS Training in Dubai
MATLAB Training in Dubai
NetSuite Training in Dubai
Pega Training in Dubai
Playwright Training in Dubai
Playwright with Python Training in Dubai
NetSuite Functional, Pega Developer, Playwright, Playwright with Python, Rebar Detailing, Agile, AI, Application Security, AWS Cloud Security, and Epicor training programs in Mumbai are designed to build strong technical and business skills. These courses cover enterprise applications, test automation, construction design, cloud security, artificial intelligence, and agile methodologies. With practical learning and real-world projects, learners can enhance their expertise, improve job readiness, and grow their careers in today’s competitive IT and engineering industries.
ReplyDeleteNetSuite Functional Training in Mumbai
Pega Developer Training in Mumbai
Playwright Training in Mumbai
Playwright with Python Training in Mumbai
Rebar Detailing Training in Mumbai
Agile Training in Mumbai
AI Training in Mumbai
Application Security Training in Mumbai
AWS Cloud Security Training in Mumbai
Epicor Training in Mumbai
Intellimindz offers specialized training in WordPress, ANSYS, AutoCAD 3DS, Data Science, Inplant Training for EEE, SAP HANA, Salesforce, and SAP BODS in Salem. These courses include hands-on learning, real-time projects, expert mentoring, certification guidance, and placement support to help learners gain practical skills and build successful careers in software, analytics, design, ERP, and engineering domains.
ReplyDeleteWordPress Training in Salem
ANSYS Training in Salem
AutoCAD 3DS Training in Salem
Data Science Training in Salem
Inplant Training in Salem for EEE
SAP HANA Training in Salem
Salesforce Training in Salem
SAP BODS Training in Salem
Intellimindz offers a diverse range of professional training programs in Coimbatore designed to help learners develop expertise in enterprise applications, software testing, analytics, business management, and engineering. The courses include Pega UI Developer, Penetration Testing, Playwright with Java, Procurement, Qlik Sense, Quantity Surveying, R Tool, SAP SD in S/4HANA, Salesforce, and SAP BODS Training. These programs combine hands-on learning, real-time project experience, and an industry-focused curriculum to help students and working professionals build practical, job-ready skills. With experienced trainers and placement-oriented guidance, Intellimindz equips learners with the knowledge and confidence required to excel in today's competitive IT and business environment.
ReplyDeletePega UI Developer Training in Coimbatore
Penetration Testing Training in Coimbatore
Playwright with Java Training in Coimbatore
Procurement Training in Coimbatore
Qlik Sense Training in Coimbatore
Quantity Surveying Training in Coimbatore
R Tool Training in Coimbatore
SAP SD in S/4HANA Training in Coimbatore
Salesforce Training in Coimbatore
SAP BODS Training in Coimbatore
Build a strong career with Intellimindz’s professional training programs in Hyderabad, offering industry-focused courses in Oracle, Oracle EBS, Playwright with JavaScript, Pega UI Developer, Penetration Testing, Procurement, Qlik Sense, R Tool, Salesforce, and SAP EWM. Learn through practical sessions, real-time projects, certification support, and placement assistance to master in-demand technologies and business skills.
ReplyDeleteOracle Training in Hyderabad
Oracle EBS Training in Hyderabad
Playwright with JavaScript Training in Hyderabad
Pega UI Developer Training in Hyderabad
Penetration Testing Training in Hyderabad
Procurement Training in Hyderabad
Qlik Sense Training in Hyderabad
R Tool Training in Hyderabad
Salesforce Training in Hyderabad
SAP EWM Training in Hyderabad
Salesforce Training in Kolkata
ReplyDeleteSAP BODS Training in Kolkata
SAP BW 4 HANA Training in Kolkata
SAP EWM Training in Kolkata
SAP PS Training in Kolkata
SAP SD Training in Kolkata
SAP SF Employee Central Training in Kolkata
Scrum Master Training in Kolkata
SDET Training in Kolkata
Selenium Automation Testing Training in Kolkata Build your career with IntelliMindz training programs in Kolkata. Learn Salesforce, SAP BODS, SAP BW 4 HANA, SAP EWM, SAP PS, SAP SD, SAP SF Employee Central, Scrum Master, SDET, and Selenium Automation Testing with industry-oriented training. Gain practical knowledge, hands-on experience, and expert guidance to develop job-ready skills and advance your career in leading technology fields.
ASAP DotNet Training in Madurai
ReplyDeleteAsset Management Training in Madurai
AWS QuickSight Training in Madurai
Azure Training in Madurai
Azure Data Factory Training in Madurai
Business Analyst Training in Madurai
C Programming Training in Madurai
CSharp With DotNet Training in Madurai
CATIA Training in Madurai
Data Modelling Training in Madurai **ASAP DotNet Training in Madurai** helps learners gain skills in application development and .NET technologies. **Asset Management, AWS QuickSight, Azure, and Azure Data Factory Training in Madurai** provide practical knowledge in cloud platforms, data analytics, and modern business solutions. **Business Analyst, C Programming, CSharp With DotNet, CATIA, and Data Modelling Training in Madurai** offer industry-focused learning with hands-on practice, expert trainers, and real-time concepts to help beginners and professionals improve technical expertise and career opportunities.
Enhance your professional skills with advanced training programs in Alteryx, AS400, Dell Boomi, Power BI, Tally, VLSI, Anaplan, Playwright with JavaScript, Product Management, and SAP VIM in Singapore. These industry-focused courses offer hands-on learning, real-time project experience, and expert mentorship covering data analytics, legacy systems, integration platforms, business intelligence, accounting software, semiconductor design, financial planning tools, test automation, product strategy, and SAP invoice management, helping learners build strong technical and business expertise for global career growth.
ReplyDeleteAlteryx Training in Singapore
AS400 Training in Singapore
Dell Boomi Training in Singapore
Power BI Training in Singapore
Tally Training in Singapore
VLSI Training in Singapore
Anaplan Training in Singapore
Playwright with JavaScript Training in Singapore
Product Management Training in Singapore
SAP VIM Training in Singapore
Enhance your technical expertise with career-focused training programs designed for aspiring professionals and working experts. Learn in-demand technologies such as CATIA, Dot Net with React, Embedded Systems, EPLAN, ETL Testing, IBM RPA, Java, JIRA, JMeter, and Linux Shell Scripting through hands-on projects, expert-led sessions, certification guidance, and placement support to boost your career opportunities.
ReplyDeleteCATIA Training in Chennai
.NET with React Training in Chennai
Embedded Systems Training in Chennai
EPLAN Training in Chennai
ETL Testing Training in Chennai
IBM RPA Training in Chennai
Java Training in Chennai
JIRA Training in Chennai
JMeter Training in Chennai
Linux Shell Scripting Training in Chennai
Developing expertise in analytics, enterprise applications, and project management technologies enhances career opportunities across industries. R Tool supports statistical computing and data analysis, while SAP S/4 HANA SD, SAP BODS, SAP BW/4 HANA, SAP EWM, SAP PS, SAP SD, and SAP SuccessFactors Employee Central strengthen enterprise resource planning and business process management skills. Salesforce improves customer relationship management capabilities, and Scrum Master training equips professionals with agile project leadership and team collaboration expertise.
ReplyDeleteR Tool Training in Singapore
SAP S/4 HANA SD Training in Singapore
Salesforce Training in Singapore
SAP BODS Training in Singapore
SAP BW/4 HANA Training in Singapore
SAP EWM Training in Singapore
SAP PS Training in Singapore
SAP SD Training in Singapore
SAP SuccessFactors Employee Central Training in Singapore
Scrum Master Training in Singapore
IntelliMindz offers industry-oriented training in Bangalore with experienced trainers, practical learning, real-time projects, certification support, flexible online and classroom batches, and placement assistance. Gain hands-on expertise in ANSYS Fluent, Apache Kafka, Asset Management, Azure, Azure Data Factory, Business Analyst, C# with .NET, CATIA, React with .NET, and Embedded Systems to build in-demand skills and accelerate your professional growth.
ReplyDeleteANSYS Fluent Training in Bangalore
Apache Kafka Training in Bangalore
Asset Management Training in Bangalore
Azure Training in Bangalore
Azure Data Factory Training in Bangalore
Business Analyst Training in Bangalore
C# with .NET Training in Bangalore
CATIA Training in Bangalore
React with .NET Training in Bangalore
Embedded System Training in Bangalore
Intellimindz offers comprehensive training programs in Gurgaon to help learners build expertise in enterprise applications, cloud platforms, software development, automation, engineering, and business technologies. The courses include Tally, VLSI, Anaplan, Playwright with JavaScript, Product Management, SAP VIM, Mendix, Red Hat OpenShift, Clinical SAS, and NetSuite Functional Training. Through hands-on projects, expert-led instruction, real-world case studies, and industry-aligned curricula, these programs equip students and working professionals with practical, job-ready skills. With flexible learning options and placement-focused support, Intellimindz prepares learners for successful careers in today's fast-growing IT, engineering, and business sectors.
ReplyDeleteTally Training in Gurgaon
VLSI Training in Gurgaon
Anaplan Training in Gurgaon
Playwright with JavaScript Training in Gurgaon
Product Management Training in Gurgaon
SAP VIM Training in Gurgaon
Mendix Training in Gurgaon
Red Hat OpenShift Training in Gurgaon
Clinical SAS Training in Gurgaon
NetSuite Functional Training in Gurgaon
```
Accelerate your career with IntelliMindz training in Chennai through industry-focused online and classroom programs. Learn from experienced trainers with hands-on projects, real-time case studies, and practical assignments. Gain job-ready skills, certification guidance, flexible batch schedules, personalized mentoring, and placement assistance to succeed in today's competitive IT and engineering industries.
ReplyDeleteApache Kafka Training in Chennai
Asset Management Training in Chennai
Azure Training in Chennai
Azure Data Factory Training in Chennai
Business Analyst Training in Chennai
C# with .NET Training in Chennai
CATIA Training in Chennai
.NET with React Training in Chennai
Embedded Systems Training in Chennai
EPLAN Training in Chennai
BOLAHIT adalah platfrom terpercaya yang menyediakan akses link situs slot777 gacor dan rtp slot88 resmi terlengkap serta selalu di perbarui setiap hari.
ReplyDeleteBOLAHIT merupakan sebuah platform yang menyediakan informasi mengenai layanan SBOBET88 serta berbagai jenis taruhan olahraga yang tersedia secara daring. Situs ini menghadirkan akses alternatif bagi pengguna yang mengalami kendala saat membuka halaman utama akibat pembatasan akses di wilayah tertentu. Selain itu, platform ini memuat penjelasan mengenai berbagai format taruhan, termasuk Mix Parlay, yang memungkinkan pengguna memahami cara kerja penggabungan beberapa pilihan pertandingan dalam satu tiket taruhan.
ReplyDeleteMenjelang penyelenggaraan Piala Dunia FIFA 2026, minat masyarakat terhadap informasi seputar jadwal pertandingan, statistik tim, performa pemain, dan berbagai jenis taruhan olahraga diperkirakan meningkat. Banyak platform informasi olahraga menyediakan pembaruan mengenai kompetisi tersebut, termasuk analisis pertandingan, data historis, serta penjelasan mengenai istilah-istilah yang umum digunakan dalam dunia taruhan olahraga. Informasi tersebut dapat membantu pembaca memahami mekanisme berbagai jenis taruhan tanpa mendorong mereka untuk berpartisipasi.
Selain menyajikan informasi mengenai kompetisi internasional, platform seperti ini umumnya menyediakan panduan penggunaan layanan, tata cara mengakses akun, serta penjelasan mengenai fitur-fitur yang tersedia. Pengguna juga dapat menemukan pembaruan terkait jadwal pertandingan, perubahan format kompetisi, dan informasi umum lainnya yang berkaitan dengan sepak bola internasional. Dengan penyajian informasi yang terstruktur dan mudah dipahami, pembaca dapat mengikuti perkembangan Piala Dunia 2026 serta memahami berbagai konsep yang berkaitan dengan taruhan olahraga dari sudut pandang yang bersifat informatif. judi bola
Intellimindz provides career-focused IT training in Chennai with expert-led courses in Dell Boomi, Power BI, Tally, VLSI, Anaplan, Playwright with JavaScript, Product Management, SAP VIM, Data Engineering, and Mendix. Learn through real-time projects, hands-on practical sessions, certification support, and placement assistance to gain industry-ready skills and accelerate your career in today's fast-growing technology landscape.
ReplyDeleteDell Boomi Training in Chennai
Power BI Training in Chennai
Tally Training in Chennai
VLSI Training in Chennai
Anaplan Training in Chennai
Playwright with JavaScript Training in Chennai
Product Management Training in Chennai
SAP VIM Training in Chennai
Data Engineer Training in Chennai
Mendix Training in Chennai
Intellimindz provides career-focused IT training in Chennai with expert-led courses in Dell Boomi, Power BI, Tally, VLSI, Anaplan, Playwright with JavaScript, Product Management, SAP VIM, Data Engineering, and Mendix. Learn through real-time projects, hands-on practical sessions, certification support, and placement assistance to gain industry-ready skills and accelerate your career in today's fast-growing technology landscape.
ReplyDeleteDell Boomi Training in Chennai
Power BI Training in Chennai
Tally Training in Chennai
VLSI Training in Chennai
Anaplan Training in Chennai
Playwright with JavaScript Training in Chennai
Product Management Training in Chennai
SAP VIM Training in Chennai
Data Engineer Training in Chennai
Mendix Training in Chennai
Learn Snowflake, SolidWorks, Technical Writing, Red Hat OpenShift, Rebar Detailing, AccelQ, WordPress, Salesforce, SAP BODS, and SAP SD with hands-on projects, real-time industry scenarios, and certification-focused training to build job-ready technical skills.
ReplyDeleteSnowflake Training in Trichy
SolidWorks Training in Trichy
Technical Writing Training in Trichy
Red Hat OpenShift Training in Salem
Rebar Detailing Course in Salem
AccelQ Training in Salem
WordPress Training in Salem
Salesforce Training in Salem
SAP BODS Training in Salem
SAP SD Training in Salem
Enhance your career with industry-focused training in Data Engineering, Mendix, Red Hat OpenShift, System Administration, CATIA Automation, Clinical SAS, MATLAB, NetSuite, Pega, and Playwright. These in-demand programs provide practical knowledge, real-world project experience, and expert guidance to help learners build technical expertise, strengthen problem-solving skills, and prepare for rewarding IT and engineering careers in Canada.
ReplyDelete```html
Data Engineer Training in Canada
Mendix Training in Canada
Red Hat OpenShift Training in Canada
System Admin Training in Canada
CATIA Automation Training in Canada
Clinical SAS Training in Canada
MATLAB Training in Canada
NetSuite Training in Canada
Pega Training in Canada
Playwright Training in Canada
```
Enhance your career with professional training in **SAP BODS, SAP BW/4HANA, SAP EWM, SAP PS, SAP SD, Scrum Master, SDET, Selenium Automation Testing, SnapLogic, and Snowflake**. These industry-focused courses offer hands-on learning, real-time projects, and expert guidance to help students and professionals develop practical skills, gain certifications, and succeed in today's fast-growing IT, SAP, automation, and cloud technology domains.
ReplyDeleteSAP BODS Training in Mumbai
SAP BW/4HANA Training in Mumbai
SAP EWM Training in Mumbai
SAP PS Training in Mumbai
SAP SD Training in Mumbai
Scrum Master Training in Mumbai
SDET Training in Mumbai
Selenium Automation Testing Training in Mumbai
SnapLogic Training in Mumbai
Snowflake Training in Mumbai