Linux uses Virtual Memory (VM) that acts as a logical layer between application memory requests and physical memory (RAM). VM abstraction hides the complexity of platform specific physical memory implementation from the application. When application accesses virtual addresses exported by VM, hardware MMU raises an event to tell the kernel that an access has occurred to an area of memory that does not have physical memory mapped to it. This event results in an exception, called Page Fault, that is serviced by Linux kernel by mapping a faulted virtual address to physical memory page.
A page is simply a group of contiguous linear addresses in physical memory. Page size is 4 KB on x86 platform. Virtual addresses are transparently mapped to physical memory by collaboration of hardware ( MMU, Memory Management Unit) and software ( Page Tables). Virtual to physical mapping information is also cached in hardware, called TLB (Translation Lookaside Buffer), for later reference to allow quick lookup into physical memory locations.
 |
| Virtual to Physical Page Translation |
A page is simply a group of contiguous linear addresses in physical memory. Page size is 4 KB on x86 platform. Virtual addresses are transparently mapped to physical memory by collaboration of hardware ( MMU, Memory Management Unit) and software ( Page Tables). Virtual to physical mapping information is also cached in hardware, called TLB (Translation Lookaside Buffer), for later reference to allow quick lookup into physical memory locations.
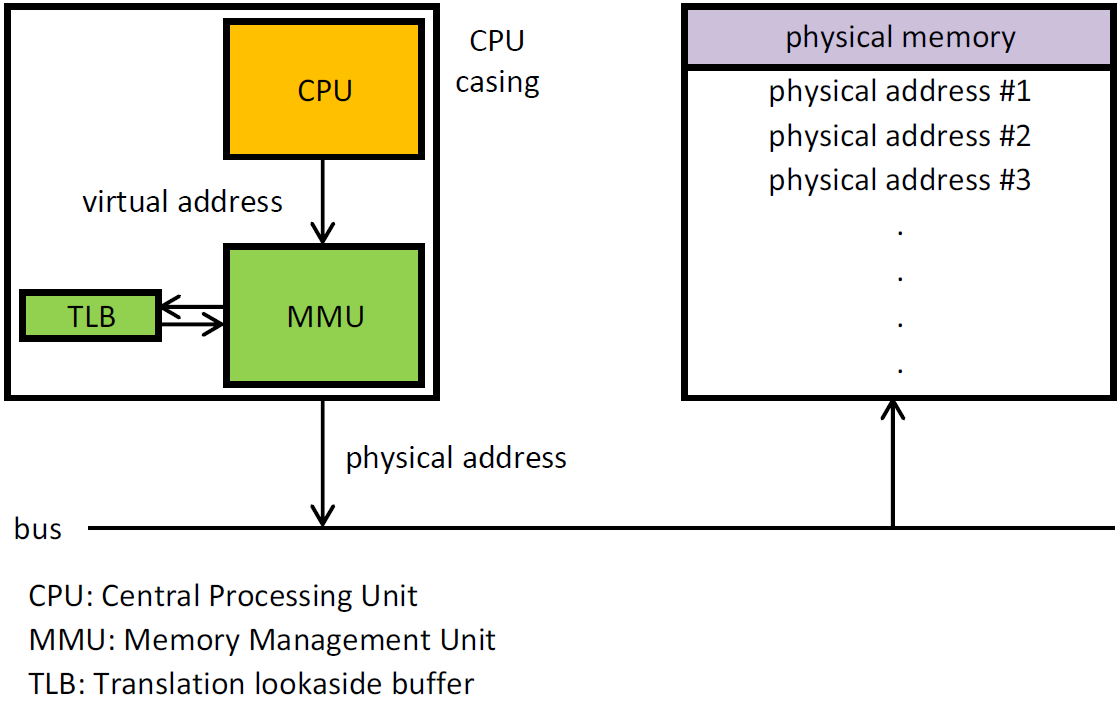 |
| Virtual to physical memory mapping |
VM abstraction offers several benefits:
- Programmers do not need to know physical memory architecture of the platform. VM hides it and allows writing architecture independent code.
- Process always see linear contiguous range of bytes in its address space, regardless of how fragmented the physical memory.
- For example: when application allocates 10 MB of memory, Linux kernel reserves 10 MB of contiguous virtual address range in the process address space. Physical memory locations where these virtual address range is mapped may not be contiguous. Only part that is guaranteed to be contiguous in the physical memory is the size of the page (4 KB).
- Faster startup due to partial loading. Demand paging loads instructions as they are referenced.
- Memory sharing. A single copy of library/program in physical memory can be mapped to multiple process address space. Allows efficient use of physical memory. "pmap -X <pid>" can be used to find what process resident memory is shared by other process or private.
- Several programs with memory footprints bigger than physical memory can run concurrently. Kernel behind the scene relocates least recently accessed pages to disk (swap) transparently.
- Processes are isolated into its own virtual address spaces and thus cannot affect or corrupt other process memory.
Two processes may use same virtual addresses, but these virtual addresses are mapped to different physical memory locations. Processes that attach to same shared memory (SHM) segment will have their virtual addresses mapped to same physical memory location.
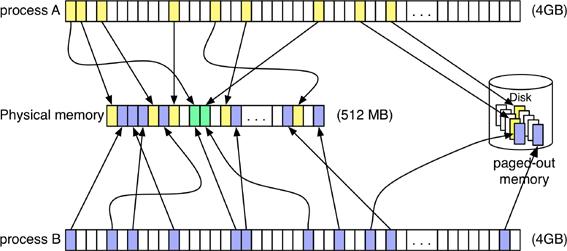 |
| Process address space can span to 32-bit or 64-bit. 32-bit address space is limited to 4GB, as compared to hundreds of Terabytes for 64-bit address space. Size of process address space limits the amount of physical memory application can use. |
Process virtual address space is composed of memory segments of type: Text, Data, Heap, Stack, Shared (SHM) memory and mmap. Process address space is defined as the range of virtual memory addresses that are exported to processes as its environment. Process address map can be viewed using "pmap -X <pid>".
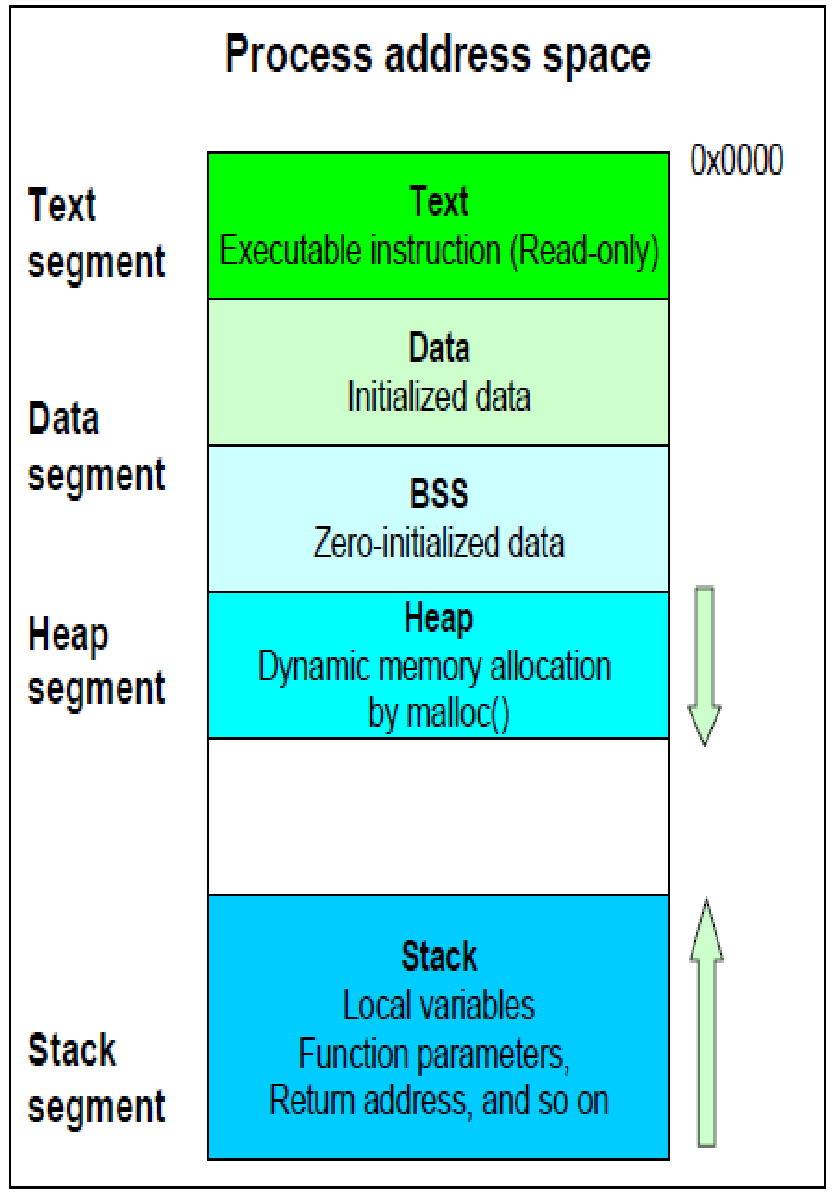 |
| various memory segments that are part of process address space |
Each memory segment is composed of linear virtual address range with starting and ending addresses, and are backed by some backing store like: filesystem or swap. Page fault is serviced by filling physical memory page from the backing store. Also, during memory shortages, data cached in physical memory pages is migrated to its backing store. Process "Text" memory segments is backed by executable file on the file system. Stack, heap, COW (Copy-on-Write) and shared memory pages are called anonymous (Anon) pages and are backed up by swap (disk partition or file). When swap is not configured, anonymous pages cannot be freed and are thus locked into memory considering no place to migrate data from these physical pages during memory shortages.
When process calls malloc() or sbrk(), kernel creates a new heap segment in the process address space and reserves the range of process virtual addresses that can be accessed legally. Any reference to a virtual address outside of reserved address range results in a segmentation violation, that kills the process. Physical memory allocation is delayed until process accesses the virtual addresses within the newly created memory segment. That means, application performing large 50GB of malloc and touching (page faulting) only 10 MB range of virtual addresses will consume only 10 MB of physical memory. One can view physical and virtual memory allocation per process using "ps", "pidstat" or "top" (Where: SIZE represents size of virtual memory segment and RSS represents allocated physical memory). Also, "pmap -X <pid>" can be used for detail view of type of process level memory allocation.
Physical memory pages used for program Text and caching file system data (called page cache) can be freed quickly during memory shortages considering data can always be retrieved from the backing store (file system). However, to free anonymous pages, data needs to be written to swap device before it can be freed.
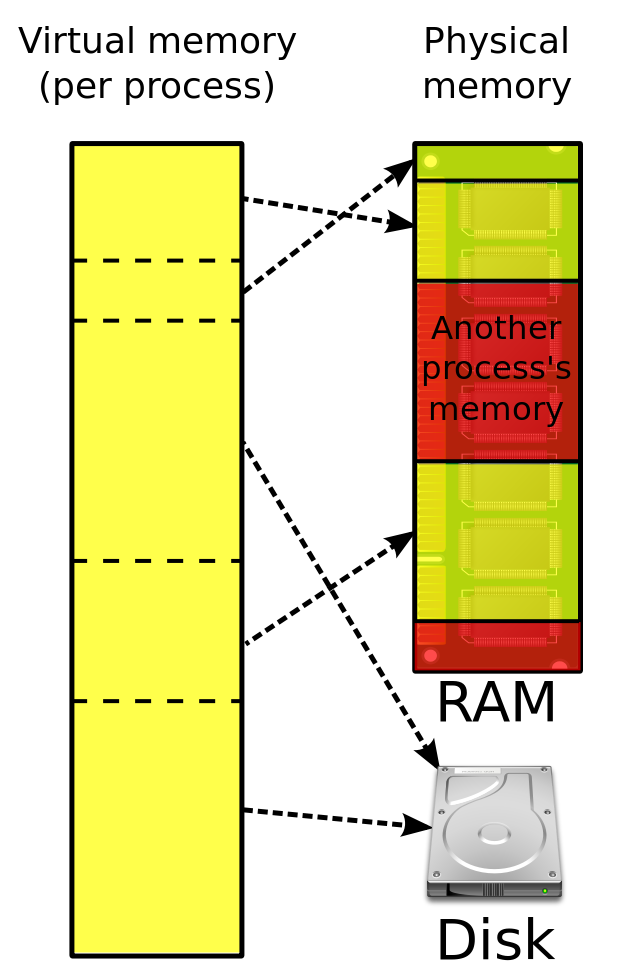 |
| Anonymous memory segments (heap, stack, cow, shared memory) are backed by swap (Disk) |
Linux Memory Allocation Policy
Process memory allocation is controlled by Linux memory allocation policy. Linux offers three different modes of memory allocations depending on the value set for tunable, vm.overcommit_memory
- Heuristic overcommit (vm.overcommit_memory=0): Linux default mode allows processes to overcommit "reasonable" amount of memory as determined by internal heuristics, that takes into account: free memory and free swap. In addition to this, memory that can be freed by shrinking the file system cache and kernel slab caches (used by kernel drivers and subsystems) is also taken into consideration.
- Pros: Uses relaxed accounting rules and it is useful for program that typically requests more memory than actually uses. As long as, there is a sufficient free memory and/or swap available to meet the request, process continue to function.
- Cons: Linux kernel makes no attempt to reserve physical memory on behalf of process, unless process touches (access) all virtual addresses in the memory segment.
- Example, Let say application, myapp, allocates 50 GB of memory, but touches only 10 GB. 40 GB of physical memory not touched by myapp is available for other applications. If any other application(s) or malicious program touches all available free memory before "myapp" get to touch it, it could trigger OOM (Out Of Memory) Killer that may terminate "myapp" in a desperate attempt to find candidates that can be killed to free memory.
- Always overcommit (vm.overcommit_memory=1): Allows process to overcommit as much memory as it wants and it always succeed.
- Pros: Wild allocations are permitted considering no restrictions on free memory or swap.
- Cons: Same as Heuristic overcommit. Application can malloc() TBs on a system with few GBs of physical memory. No failure until all pages are touched and that triggers OOM Killer.
- Strict Overcommit (vm.overcommit_memory=2): Prevents overcommit by reserving both virtual memory range and physical memory. No overcommit means no OOM Killer. Kernel keeps track of amount of physical memory reserved or already committed. "cat /proc/meminfo" reports metrics such as: CommitLimit, Committed_AS to help estimate memory available for allocation. Since strict overcommit mode does not take free memory and swap into consideration, one should not use free memory or swap metrics (reported by free, vmstat ) to discover memory available. To calculate current overcommit or allocation limit, one should use the equation: "CommitLimit - Committed_AS". Kernel tunable "vm.overcommit_ratio" sets overcommit limit for this mode. Overcommit limit is set to: Physical Memory x overcommit_ratio + swap. Overcommit limit can be raised by setting vm.overcommit_ratio tunable to a bigger value (default 50% of physical memory).
- Pros: Disables OOM Killer. Failure at the startup has lower production impact than being killed by OOM Killer while serving production load. Solaris OS offers only this mode. Strict overcommit does not use free memory/swap for overcommit limit calculations.
- Cons: No overcommit allowed. Memory allocated but not used by application may not be used by other application. A new program may fail to allocate memory even when the system is reporting plenty of free memory. This is due to reservation against the physical memory on behalf of existing processes. Monitoring for free memory becomes tricky. Some badly written applications do not handle memory allocation failures. Inability to check memory failures may results in corrupted memory and random hard to debug failures.
- Note: Memory not used by the application can still be used for filesystem cache considering page cache memory can be freed when application needs it.
NOTE: For both heuristic and strict overcommit, the kernel reserves a certain amount of memory for root. In heuristic mode, 1/32nd of the free physical memory. In Strict overcommit mode it is 1/32nd of the percent of real memory that you set. This is hard coded in kernel and cannot be tuned. That means a system with 64GB will reserve 2GB for root user.
What causes OOM Killer
Criteria used to find the candidate process some time kills the most critical process. There are few options available to deal with OOM Killer:
- Disable OOM Killer by changing kernel memory allocation policy to strict overcommit.
- $sudo sysctl vm.overcommit_memory=2
- $sudo sysctl vm.overcommit_ratio=80
- Opt out the critical process from OOM Killer consideration.
- $ echo -17 > /proc/<pid-critical-process>/oom_adj
- Opting out critical server process may sometime not be enough to keep system functioning. Kernel still has to kill processes in order to free memory. In some cases, automated reboot server to deal with OOM Killer may the better option.
- $sudo sysctl vm.panic_on_oom=1
- $sudo sysctl kernel.panic="number_of_seconds_to_wait_before_reboot"
File System Cache Benefits
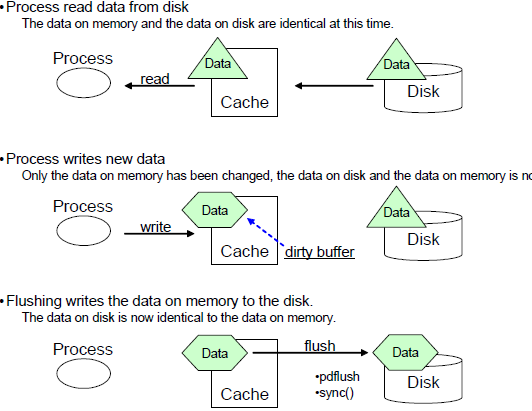
Linux uses free memory that is not being used by application for caching file system pages and disk blocks. Memory used by file system cache is counted as free memory and available when needed (after writing modified pages to backing store or disk). Linux "free" reports file system cache memory as free memory. Benefit of having file system cache is improved performance of application file system reads and writes:
- Read: When application reads from a file, kernel performs a physical IO to read data blocks from the disk. Data is cached in the file system cache for later use to avoid physical read. When application requests the same block, it only requires a logical IO (reading from filesystem page cache) and that improves application performance. Also, file systems prefetch (read ahead) blocks, when sequential IO pattern is detected, in an anticipation that application will request next adjacent blocks. This also help reduce IO latencies.
- Write: When application writes to a file, kernel caches data into page cache and acknowledges completions (called buffer writes). Also file data sitting in filesystem cache can be updated multiple times (called write cancelling) in memory before kernel schedules dirty pages to be written to disk.
File System cache improves both read and write performance
Dirty pages in file system cache are written by "flusher" (old name is pdflush) kernel thread. Dirty pages are flushed periodically when the proportion of dirty buffers in memory exceeds a certain threshold (kernel tunable). File system cache improves application IO performance by hiding storage latencies.
HugeTLB or HugePages Benefits
 |
| TLB miss results in walk to memory resident page tables |
As discussed earlier,TLB (Translation Lookaside buffer), integrated onto a cpu chip, caches virtual to physical translation. When translation is not found in TLB (event is called TLB miss), it results in expensive walk to memory resident page tables to find virtual to physical memory translation. TLB cache hit is becoming more important due to increasing disparity in cpu and memory speed and memory density. Frequent TLB miss may negatively impact application performance. TLB is a scarce resource on cpu chip and Linux kernel tries to make best use of limited TLB cache entries. Each TLB cache entry can be programmed to provide access to contiguous physical memory addresses of various sizes: 4 KB, 2 MB or 1 GB. Linux HugeTLB feature allows application to use large pages: 2 MB, 1 GB than the default 4 KB size.
 |
| Intel Haswell core has 64 entries for caching 4 KB page translation, 32 entries for 2 MB and 4 entries for 1 GB pages in L1 DTLB. There is also a unified (shared) L2 TLB that can hold translations for 1024 4 KB or 2 MB pages. Once the virtual address has been calculated, processor probes the TLB cache for v->p translation and then fetches the data in 64 bytes chunk from the physical memory location into L1/L2 hardware caches |
Pros and Cons of Linux HugeTLB feature:
Pros:
- HugeTLB may help reduce TLB misses by covering bigger process address space. For Intel Haswell processor:
- 4 KB page can cover: 64x4 + 1024x4 = 4 MB
- 2 MB page can cover: 32x2048 +1024x2048 = 2 GB
- 1 GB page can cover: 4GB
- TLB miss with HugeTLB is cheaper to service. Virtual to physical memory translation for 4KB pages via page tables require multiple levels of translations (4 levels for standard 48-bit virtual address space). Larger page size require fewer page table entries and levels are shallower. This reduces memory latency due to 2 level instead of 4 level page tables access and physical memory used for page table translation.
- Reduces page fault rates. Each page fault can fill 2 MB or 1GB physical memory than 4 KB. Thus makes the application to warm up much faster.
- Application performance improvement with HugeTLB depends on application access pattern. If application access pattern shows data locality, HugeTLB will help. However, if application reads from random locations or only few bytes from each page (large hash table lookup) and the working set is too big to fit in TLB cache, then 4 KB page size may offer better performance.
- 1 GB page may offer best performance when working set fits in 4GB physical memory. Even when the working set is bigger, page table walk with 1GB will be much quicker.
- Huge Pages are locked in memory and thus are not candidate for page out during memory shortages
- Large pages also improve the process of memory pre-fetching by eliminating the need to restart pre-fetch operation at 4K boundaries
- Transparent HugePages benchmarks results showing remarkable improvment
Cons:
- Huge Pages require upfront reservation. System Admin is required to set kernel tunable to desired number of HugePages: vm.nr_hugepages=<number_of_pages>
- Linux Transparent Huge Pages (THP) feature does not have upfront cost. THP is still new and has limited uses and known performance bugs. More THP testing is needed!
- Application should be HugePage aware. For example: java application should be started with "-XX=+UseLargePages" option in order to use large pages for java heap. Otherwise, pages allocated may not be used for any purpose. One can monitor Huge Page usage using "cat /proc/meminfo|grep PageTables"
- HugePages require contiguous physical memory of sizes: 2 MB and 1GB. Request for large pages may fail if the system is running for a longer period and most of the memory is demoted to 4 KB chunks.

